はじめに # LLM の安全性やガードレールは、サービスごとに説明が分かれ、一国の政府が横断的に示す「公式の基準やルール」がすぐ手元にあるわけではありません。評価を第三者が検証したり、同じ手順を繰り返したりするには、文章だけでは足りない場面があります。
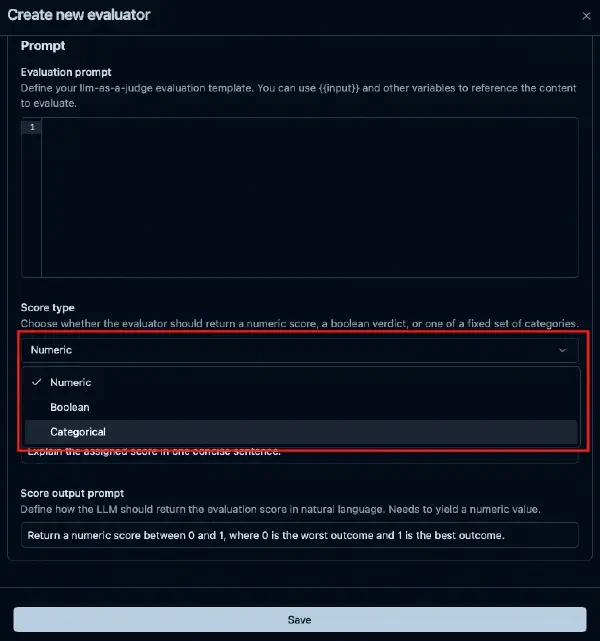
本記事でわかること # LLM-as-a-Judgeで数値スコアを使うことの問題点 Langfuseのカテゴリ型・Boolean型スコアを使って、直感的な Evaluator を設計する方法 JSON Schemaによる型安全な評価出力の仕組み RAG精度・コンテンツ安全性・サポートチケット分類など実務ユースケースへの適用例 対象読者 # Langfuseで LLM-as-a-Judge(自動評価)を運用している方 評価スコアのしきい値設定に迷いを感じている方 評価結果をダッシュボードで分析しやすくしたい方 「0.7以上なら合格」という設計の脆さ # 本番LLMアプリの評価パイプラインを運用していると、自動評価(LLM-as-a-Judge)はもはや欠かせない仕組みです。人間がすべてのトレースをレビューするのは非現実的なため、LLMに評価させるアプローチが普及してきました。
LLMアプリケーションの開発で、こんな経験はないでしょうか。
「先週と同じ条件で実験したいのに、データセットを更新したから再現できない…」
「評価データを改善したいけど、過去の結果と比較できなくなるのが怖い…」
こんにちは。ガオ株式会社の黒澤です。
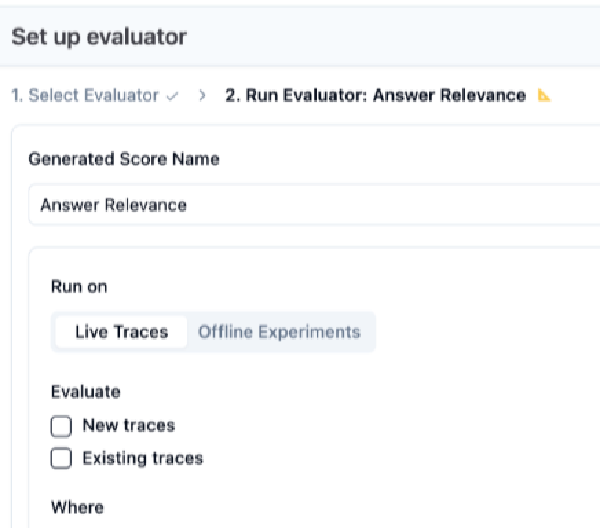
Langfuse v3.153.0 で [PR #11861 ](https://github.com/langfuse/langfuse/pull/11861 ) がマージされ、LLM-as-a-Judge を Observation 単位で実行できるようになりました。本記事ではその背景と使い方をまとめます。
Geminiの性能向上によりOCRは実用的になりましたが、高精度を目指すならプロンプト調整は必須です。しかし、調整のたびに画像と結果を目視で見比べるのは、手間がかかりミスも誘発します。
はじめに # LLMアプリケーションの開発において、プロンプトの改善は避けて通れない作業です。しかし、プロンプトを変更するたびに、こんな不安を感じたことはありませんか?
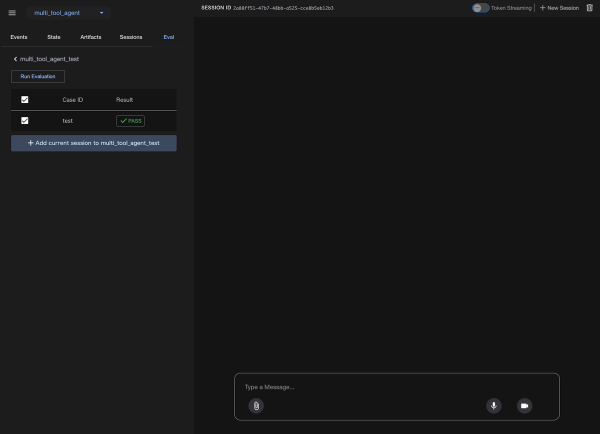
最近話題の Google 製 AI エージェントフレームワーク「Agent Development Kit (ADK)」を触ってみました! Gemini モデルとの連携がしやすく、柔軟なエージェント開発が可能とのことで、期待が高まります。エージェントが自律的にツールを使うのは凄いですが、ちゃんと意図通り動くか、修正で壊れないかを確認する「評価」も重要ですよね。
更新日:2025年4月25日
LLMOps とは? # LLMOps(Large Language Model Operations)とは、大規模言語モデル(LLM)を利用した生成AIアプリケーションの開発から運用、改善までを一貫して管理するための考え方や仕組み(フレームワーク)です。多くの企業では、自社でモデルをゼロから構築するのではなく、OpenAI、Google、Anthropic などが提供する基盤モデルを活用し、プロンプト設計やファインチューニング(微調整)を通じて目的に合った生成AIアプリケーションを開発しています。LLMOpsは、こうした開発・運用プロセスを効率化し、品質管理やガバナンスを実現する上で重要な役割を果たします。
更新日:2025年4月10日
1.初めに # 近年、AI 技術、特に大規模言語モデル(LLM)の進化は目覚ましく、様々な分野での活用が進んでいます。しかし、LLM をビジネスに適用する上で、その品質をどのように評価するかが大きな課題となっています。