Langfuse の公式ドキュメントに掲載されている Cookbook「Migrating Data Between Langfuse Projects (Python SDK v4) 」を、4 つの移行パターンで実際に実行してみました。移行はおおむね成功しましたが、UI に出るものと出ないものが分かれ、見落としやすい落とし穴がいくつかありました。本記事では、特定の検証環境における観測結果と再現時の注意点を整理します。Cloud / セルフホスト / リージョンによる差分が Langfuse の正式仕様なのか、Feature flag や Preview UI・検証時点の実装差なのかは、本記事の範囲では切り分けていません。
2026年5月末、Langfuse に組み込まれた MCP サーバ機能が大幅に拡張されました。SaaS版では 2026-05-29 の changelog で告知され、self-host版では v3.176.0(2026-05-28)で標記の機能が一通り出揃っています。これまでLangfuseが提供してきた組み込みのMCPサーバ機能はプロンプト管理機能だけでしたが、今回一連の拡張で observation・metrics・scores・datasets・comments・annotation queues など、プロジェクトデータの大半を MCP 経由で扱えるようになりました。
本記事でわかること # 対象環境: 本記事の内容はLangfuse Cloud環境が対象です。セルフホスト環境では現時点でMonitors機能は利用できません。
概要 # DeepTeam は LLM アプリの脆弱性を自動で突きにいく OSS(Confident AI 製、DeepEval の兄弟) 50+ の脆弱性カテゴリと多数の攻撃手法(バージョンにより増減)を組み合わせてくれるので、自分で攻撃プロンプトを考えなくていい Acme 社という架空のヘルプデスク Bot にプロンプトインジェクション × 3 をぶつけたら、Gemini 2.5 Flash + 短いシステムプロンプトで 今回の 3 ケースでは漏洩なし (Mitigation 100%) Langfuse に @observe + create_score を入れるだけで、攻撃シミュレーションの結果が 時系列ダッシュボード になる 単発の CLI 結果で終わらせず、Trace・Score・Session として保存して PR ごと・リリースごとに差分を追える状態を作るのが本記事のゴール 1. DeepTeam とは # DeepTeam は、LLM アプリに対する 攻撃シミュレーション(英語圏では “red teaming”)を自動化するフレームワークです。評価フレームワーク DeepEval の兄弟プロダクトで、Confident AI が出しています。
TL;DR # 後編で指摘した NFKD 正規化の不整合(カウンターとハイライトの食い違い)は、Langfuse 本体の PR #12961 / #13038(v3.166.0)で解消されました。 上流 @codemirror/search に出した PR #19 自体はマージされず、取り下げになりました。 ただしその後、@codemirror/search 6.7.0 で、PR #19 とは異なるアプローチ(マッチに precise フラグを付与し、置換側が安全に弾けるようにする方式)によって SearchCursor の正規化境界の問題に対処されています。 これは PR #19 がそのまま採られたわけでも、Langfuse v3.166.0 の修正そのものでもありません。Langfuse は v3.166.0 時点で @codemirror/search を ^6.6.0 と宣言しており、本記事執筆時点の main では ^6.7.0 に引き上げられています。 はじめに # 以前、Langfuse v3.158.0 で追加されたメッセージウィンドウ内検索機能(PR #12578)について、2回に分けて記事を書きました。
本記事でわかること # LLM-as-a-Judgeの「苦手な評価」とは何か Langfuseのコード評価(Code Evaluators)機能の概要と使い方 コード評価をLLM評価と組み合わせた実践的な運用パターン INACTIVEなエバリュータへの手動バッチ実行を活用した安全な本番導入フロー 対象読者 # LangfuseでLLM-as-a-Judgeを使っているエンジニア 評価コストや判定のブレに課題を感じている方 Langfuseの評価機能を本番導入する前に安全に試したい方 LLM-as-a-Judgeだけでは足りないケース # LLMアプリを本番運用していると、こんな疑問が浮かぶことがあります。「この評価、本当にLLMが必要?」
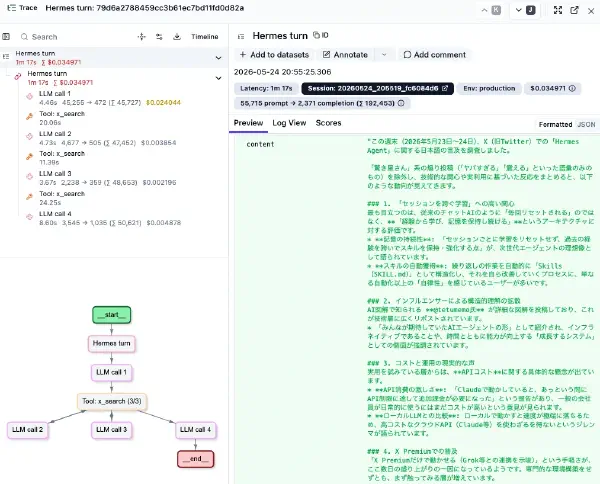
ガオ株式会社では、社内およびグループ企業間の業務で自律型エージェント Hermes Agent (NousResearch/hermes-agent) の活用を進めています。
エージェントが Tool を呼び出しながら自律的に業務を進めるようになると、LLM API call 単位のログだけでは挙動を追いきれません。さらに自律型エージェントの場合、人手が介在せず判断と実行が連続して走るため、観測性 — 後から誰が何を要求し、エージェントが何を判断し、どの Tool をどう実行したかを追える状態 — が、従来以上にガバナンスや内部統制の観点で重要になります。
こんにちは。ガオ株式会社の黒澤です。LangfuseのCloud版にて、Experiments が独立した機能としてメニューから選択できるようになりました。本記事では、Experimentsでどのようなことができるのかということを、変更点や動作確認を交えて解説します。
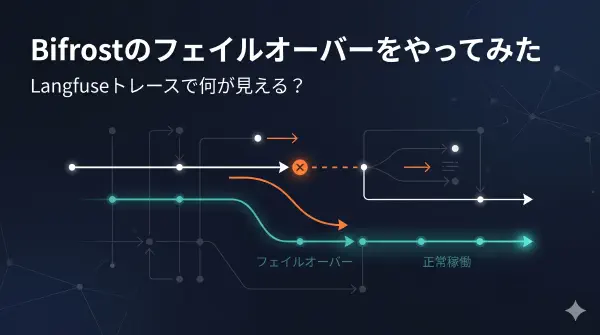
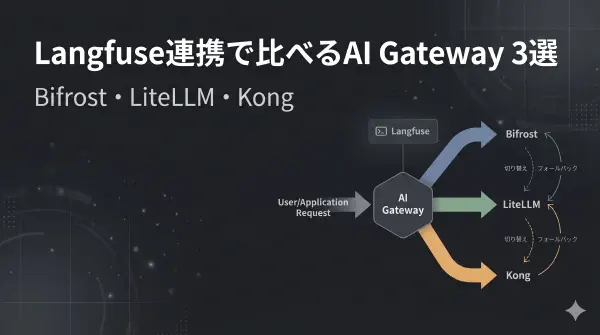
こんにちは。ガオ株式会社の黒澤です。前回 の記事では、AI Gatewayの製品を3つ紹介しました。この記事では、その中からBifrostを使用して、フォールバック機能がどのように動作して、Langfuseで可視化されるかを解説します。
こんにちは。ガオ株式会社の黒澤です。LLMアプリケーションを複数開発する環境では、それらを統合する基盤であるAI Gatewayを活用するケースがあります。本記事では、AI Gatewayとして3つの製品を、Langfuseと組み合わせた場合のポイントとともに解説します。
はじめに # LLM の安全性やガードレールは、サービスごとに説明が分かれ、一国の政府が横断的に示す「公式の基準やルール」がすぐ手元にあるわけではありません。評価を第三者が検証したり、同じ手順を繰り返したりするには、文章だけでは足りない場面があります。
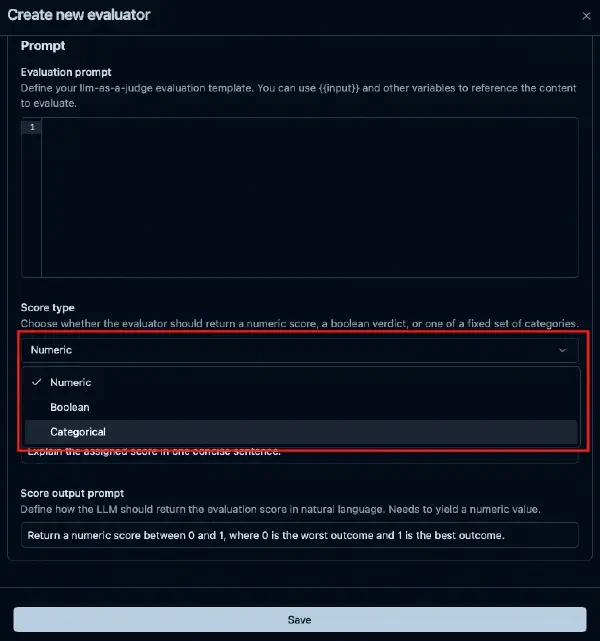
本記事でわかること # LLM-as-a-Judgeで数値スコアを使うことの問題点 Langfuseのカテゴリ型・Boolean型スコアを使って、直感的な Evaluator を設計する方法 JSON Schemaによる型安全な評価出力の仕組み RAG精度・コンテンツ安全性・サポートチケット分類など実務ユースケースへの適用例 対象読者 # Langfuseで LLM-as-a-Judge(自動評価)を運用している方 評価スコアのしきい値設定に迷いを感じている方 評価結果をダッシュボードで分析しやすくしたい方 「0.7以上なら合格」という設計の脆さ # 本番LLMアプリの評価パイプラインを運用していると、自動評価(LLM-as-a-Judge)はもはや欠かせない仕組みです。人間がすべてのトレースをレビューするのは非現実的なため、LLMに評価させるアプローチが普及してきました。