本記事でわかること#
- LLM-as-a-Judgeで数値スコアを使うことの問題点
- Langfuseのカテゴリ型・Boolean型スコアを使って、直感的な Evaluator を設計する方法
- JSON Schemaによる型安全な評価出力の仕組み
- RAG精度・コンテンツ安全性・サポートチケット分類など実務ユースケースへの適用例
対象読者#
- Langfuseで LLM-as-a-Judge(自動評価)を運用している方
- 評価スコアのしきい値設定に迷いを感じている方
- 評価結果をダッシュボードで分析しやすくしたい方
「0.7以上なら合格」という設計の脆さ#
本番LLMアプリの評価パイプラインを運用していると、自動評価(LLM-as-a-Judge)はもはや欠かせない仕組みです。人間がすべてのトレースをレビューするのは非現実的なため、LLMに評価させるアプローチが普及してきました。
しかし、LLM-as-a-Judgeを数値スコアのみで運用していると、同じ問題が繰り返し発生します。
「このスコアのしきい値、なぜ0.7にしているんでしたっけ?」
チームで評価パイプラインを構築していると、必ずといっていいほど出てくる問いです。LLMに「0〜1のスコアで返せ」と指示しても、その数値の根拠は曖昧になりがちです。「0.8だと厳しすぎる」「0.65でも許容範囲では?」という議論が発生し、しきい値の意味がレビュアーごとにぶれてしまいます。
多段階評価になると、問題はさらに顕著になります。「良い/普通/悪い」という直感的な判断を、0.8/0.5/0.2という数値に変換して扱うことを強いられます。ダッシュボードで「平均スコア: 0.62」を見ても、それが「ほぼ普通」なのか「悪いに近い」のかを直感的に把握するのは難しい。
さらに技術的な問題もあります。スキーマ検証なしの実装では、プロンプトに「0〜1のスコアで返せ」と指示しても、LLMが期待どおりの形式で返さないケースがあります。
# プロンプト
以下の回答を0〜1のスコアで評価してください。スコアのみを返してください。
回答: {output}
参照ドキュメント: {reference}
# LLMの実際の出力例
"0.75" → パース可能
"約0.8程度です" → パース不可
"スコア: 0.7" → パース不可(実装次第)スキーマ検証がなければ、こうした出力はパースエラーを引き起こし、評価パイプラインが気づかないうちに壊れてしまうリスクがあります。
カテゴリ型スコアで何が変わるか#
もちろん、Numeric スコアが不要になるわけではありません。類似度、網羅性、有用性のように連続的な度合いを見たい場合は Numeric が自然です。一方で、RAG応答の正誤分類や安全性判定のように、最終的な運用判断がラベルで表現されるケースでは Categorical が向いています。
Langfuseの LLM-as-a-Judge Evaluatorでは、スコアタイプとして Numeric / Boolean / Categorical の3種類を選択できます。
最も大きな変化は、評価結果が「意味のあるラベル」として出力されるようになることです。数値スコアでは「平均 0.62」としか見えなかった結果が、自分で定義したカテゴリ名で直接出力されます。
例えば次のようなカテゴリを定義できます。
| カテゴリ名 | 説明 |
|---|---|
fully_correct | 参照ドキュメントと完全に一致している |
partially_correct | 一部一致しているが情報が不足または誤り混入 |
incorrect | 参照ドキュメントと矛盾、または根拠なし |
これにより、次のことが実現します。
- ダッシュボードで直感的に把握できる — 「
incorrectが今週20件」という形で集計でき、数値を解釈する手間がなくなる - 問題トレースをすぐ特定できる —
incorrectのトレースだけフィルタして、原因を調査できる - 評価基準がチームで共有しやすくなる — 「0.7以上なら合格」という曖昧なしきい値の代わりに、カテゴリの定義そのものが基準になる
なお、定義したカテゴリは自動的に JSON Schema にコンパイルされ、LLMへの構造化出力リクエストに組み込まれます。これにより、LLMが定義外の値を返す可能性を大幅に下げられるため、パースエラーによって評価パイプラインが壊れるリスクを大幅に抑制できます(詳細は次セクション)。
仕組み:JSON Schemaによる型安全な出力#
カテゴリ型が「なぜパースエラーを起こしにくいのか」は、Langfuseの内部実装を見ると理解しやすくなります。Evaluator でカテゴリを定義すると、Langfuseは内部でこのようなJSON Schemaを生成します。
{
"type": "object",
"properties": {
"score": {
"type": "string",
"enum": ["fully_correct", "partially_correct", "incorrect"]
},
"reasoning": {
"type": "string"
}
},
"required": ["score", "reasoning"]
}このスキーマが評価用LLMへの 構造化出力(Structured Outputs) のリクエストに使用されます。OpenAI / Anthropic / Gemini など主要なプロバイダーの構造化出力機能を通じてスキーマ制約を適用できるため、成功時には enum に含まれるカテゴリ名のいずれか一つを返すように制約できます。
ただし、利用する評価モデルやプロバイダー側の構造化出力対応状況に依存するため、評価ログの失敗率や例外ケースは運用上モニタリングしておく必要があります。
評価ログ画面では、数値の代わりにカテゴリ名がそのまま表示されます。「incorrect が今週20件」という集計が一目でわかり、数値を解釈する手間がなくなります。
使い方:Evaluator の作成#
ステップ 1:Evaluator を新規作成する#
Langfuse の Evaluators 画面から Set up Evaluator を選択し、Custom Evaluator を作成します。作成画面では、評価に使うモデル、評価対象、プロンプト、変数マッピング、スコアタイプを設定します。スコアタイプには Numeric / Boolean / Categorical を選択できます。
ステップ 2:カテゴリを定義する#
Categorical を選択すると、カテゴリ入力フィールドが展開されます。カテゴリ名と説明文を自由に入力し、「Add category」ボタンで項目を増やせます。
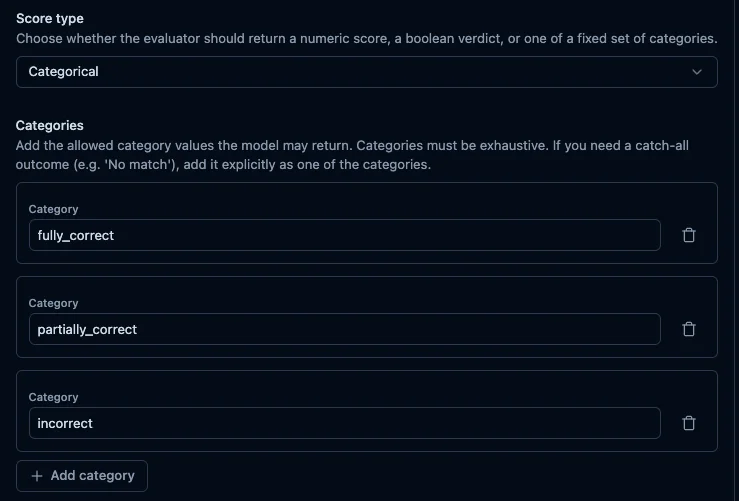
カテゴリ名には、ダッシュボードでの集計や後続処理でそのまま使いやすい英数字の識別子を推奨します(例: pass / fail よりも fully_correct / incorrect のように意味が明確なもの)。
評価結果の見方#
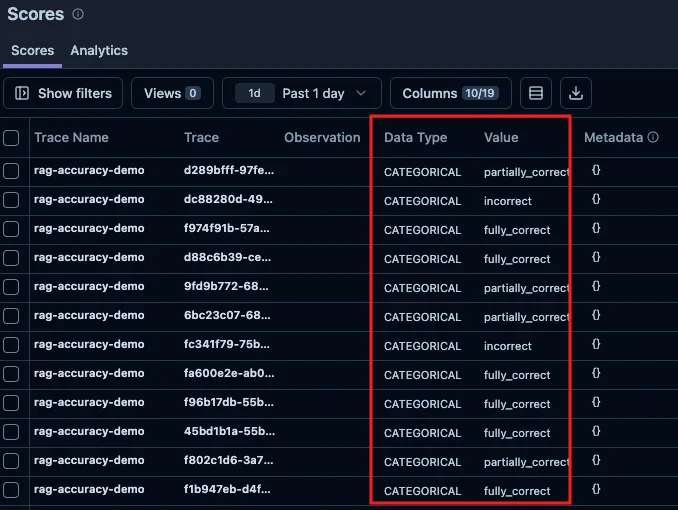
評価が実行されると、Scores 画面にカテゴリ名がそのまま表示されます。数値ではなく incorrect / partially_correct / fully_correct というラベルで記録されるため、結果を解釈する手間がありません。
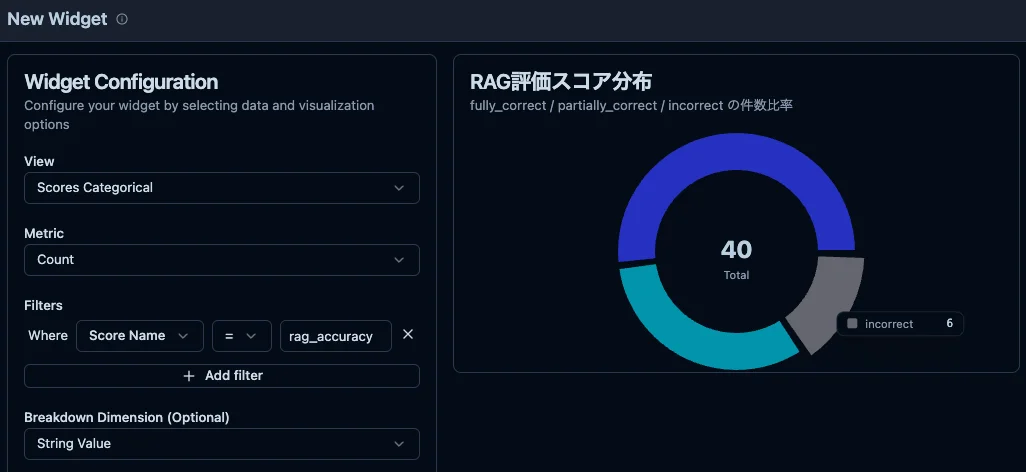
カテゴリ別の分布はダッシュボードウィジェットで可視化できます。「incorrect が全体の何%か」という形で把握できるため、数値スコアの平均値とは異なる直感的な見え方になります。
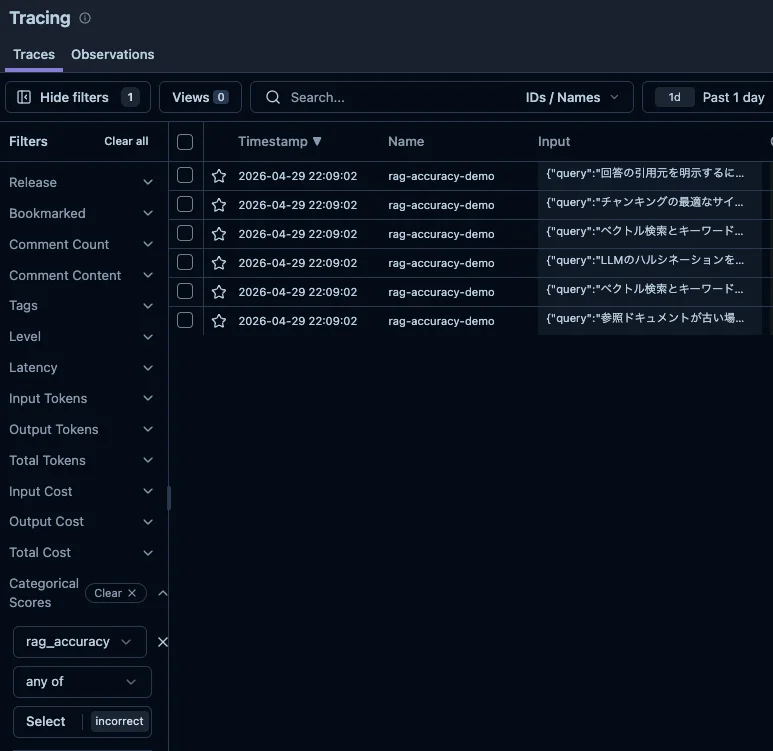
Tracing 画面の Categorical Scores フィルタを使うと、特定カテゴリのトレースだけを絞り込めます。例えば rag_accuracy の incorrect で絞ることで、問題のあるトレースだけを一覧し、どんな入力パターンで発生しやすいかを直接確認できます。
実務での活用シーン#
RAG応答の正確性評価#
RAGシステムで「参照ドキュメントと回答が一致しているか」を評価する場合に最も直感的に使えます。数値スコアの平均値では「全体的に低め」としか把握できなかったものが、カテゴリ別の分布として見ることで、インデックス品質の問題なのかプロンプトの問題なのかを切り分けやすくなります。
| カテゴリ | 意味 |
|---|---|
fully_correct | 参照ドキュメントと完全に一致 |
partially_correct | 一部一致しているが情報が不足または誤り混入 |
incorrect | 参照ドキュメントと矛盾、または根拠なし |
カテゴリ型スコアを導入すると、運用フローが次のように整理できます。
- 全トレースをカテゴリ型評価器で自動分類
- ダッシュボードで
incorrectの件数・割合を追跡し、傾向を把握 incorrectのトレースだけフィルタして、どんな質問パターンで発生しやすいかを分析- ユーザーフィードバックスコアと重ねることで、例えば「
partially_correctの回答ほど満足度が低い傾向がある」といった相関を発見し、改善の優先順位付けに活かせる場合がある
コンテンツ安全性の判定#
safe / needs_review / blocked のカテゴリを定義することで、ルールベースのしきい値設定なしに3段階の安全性ジャッジを自動化できます。needs_review の件数が増えたタイミングを検知して人間によるレビューキューに回す、というフローとの相性がよいです。
サポートチケットのルーティング#
LLMアプリがカスタマーサポートに関わる場合、問い合わせ内容への対応品質を resolved / needs_followup / escalate といったカテゴリで分類できます。数値スコアの平均では見えにくい「エスカレーションが必要なケースの件数」を直接トラッキングできます。
シンプルな合否判定には Boolean#
「条件を満たしているか否か」だけを評価したい場合は Boolean タイプが適しています。true / false の二値評価になるため、数値のしきい値設定は不要になります。一方で、true と false をどう判定するかという基準自体は明文化しておく必要があります。数値スコアを0.5でカットするような運用をしているなら、Booleanへの置き換えを検討する価値があります。
LLM-as-a-Judge Evaluator で選ぶ3タイプの使い分け#
どのスコアタイプを選ぶか迷った場合は、次の表を参考にしてください。
なお、Langfuse の score data type 全体には Text もありますが、本記事では LLM-as-a-Judge Evaluator で主に使う Numeric / Boolean / Categorical に絞って説明します。
| タイプ | 向いているケース | 例 |
|---|---|---|
| Numeric | 連続的な品質スコアや類似度 | BLEU スコア、コサイン類似度 |
| Boolean | 単純な合否・条件充足の確認 | フォーマットチェック、ポリシー違反判定 |
| Categorical | 多段階分類や意味のあるラベル付け | 正確性レベル、安全性分類、感情分析 |
注意点#
スコアタイプは作成後に変更できない#
一度作成した Evaluator のスコアタイプ(Numeric / Boolean / Categorical)は後から変更できません。評価結果の一貫性を保つための意図的な設計です。Evaluator を設計する際は、スコアタイプを最初にしっかり決めておきましょう。
スコアタイプを変えたい場合は、新しい Evaluator を作成し、以降のトレースから新 Evaluator を使うことになります。
カテゴリ定義のルール#
- カテゴリは 最低2つ 必要(1つだけでは評価にならないため)
- カテゴリ名の 重複は不可(バリデーションエラーになります)
単一分類と複数分類を分けて設計する#
Categorical score は、基本的には「この評価結果はどのカテゴリか」を表す分類に向いています。一方で、安全性判定や問い合わせ分類のように、複数のラベルが同時に当てはまるケースでは、Allow multiple matches を有効化して複数カテゴリを選択させる設計も考えられます。この場合、選ばれたカテゴリごとに score が作られます。
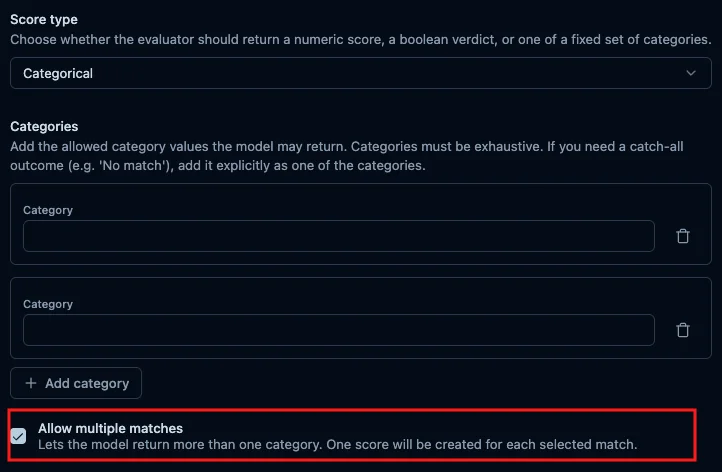
ただし、RAG正確性のように fully_correct / partially_correct / incorrect が排他的な関係にある場合は、複数選択ではなく単一分類にしておくほうが、集計・改善判断がわかりやすくなります。
カテゴリ設計で避けたいパターン#
Categorical score を使う場合でも、カテゴリ定義が曖昧だと評価結果は安定しません。特に避けたいのは、カテゴリ同士が重なっているケースです。
例えば minor_issue と partially_correct のように、どちらにも入りそうなカテゴリを並べると、Judge モデルの判断がぶれやすくなります。カテゴリはできるだけ排他的にし、各カテゴリの説明には「何を満たせばそのカテゴリか」「何を満たさなければ別カテゴリか」を明記しておくのが実務上重要です。
カテゴリ化しても、人間の検証は不要にならない#
Categorical score は、評価結果の解釈と運用をわかりやすくしますが、Judge モデルの判断そのものを保証するものではありません。LLM judge の判断はモデル間・実行条件間で揺れうることが指摘されており、カテゴリ型は解釈性や運用性を上げる設計であって、評価基準の妥当性確認や人間レビューを不要にするものではありません。
重要な評価器では、少量のサンプルを人間がレビューし、カテゴリ定義と Judge の判断が合っているかを定期的に確認することが重要です。
既存 Evaluator への影響はない#
後方互換性は維持されています。既存の数値スコアの Evaluator はそのまま動作します。新規 Evaluator を作成する際にスコアタイプを選択する形なので、移行コストはありません。
まとめ#
カテゴリ型スコアの導入によって、LLM-as-a-Judgeの設計がより直感的になりました。
- 曖昧なしきい値設定が不要になる — カテゴリの定義そのものが基準になり、評価基準がチーム内で共有しやすくなる
- 問題トレースをすぐ特定できる — カテゴリ値での絞り込みにより、原因調査の起点にできる
- ダッシュボードでの分析が直感的になる — 数値を解釈する手間なく「どのカテゴリが何件か」をそのまま把握できる
なお、コサイン類似度やBLEUスコアのように連続的な評価が必要なケースでは、引き続き Numeric が適しています。カテゴリ型はすべての評価を置き換えるものではなく、「離散的な分類」に特化した選択肢です。
既存の数値スコアの Evaluator で「しきい値の根拠が曖昧」と感じているものがあれば、カテゴリ型への移行を検討してみてください。LLMアプリの評価設計の質を上げる、比較的コストの低い改善です。