はじめに#
Langfuse ライフ、いかがお過ごしですか。
近いうちに Langfuse が v3 から v4 にアップデートされることを、すでにご存じでしょうか。現在、Langfuse の Web UI の左下に、v4 向けプレビュー体験のトグル「Fast (Preview)」(以前は「v4 Beta」)が表示されています。これをオンにすると、「Langfuseが速くなる」という旨が書かれた確認ダイアログが出ると思います。
想定読者:Langfuse v3 の画面や 旧バージョンSDK を触ったことがあるが、v4 の概要をまだ掴めていない方。
- 本記事で触れる v4 / Fast (Preview) の話は、現時点では主に Langfuse Cloud のプレビュー体験を念頭に置いています。UI で新しい体験に切り替えられますが、すべての画面がすでに新データモデルへ移行済みというわけではありません。OSS / セルフホスト向けの移行パスは公式が作業中と明示しており、今後正式な案内が予定されています。
- また、新しい UI でデータをほぼリアルタイムに近いタイミングで見るには、後述のPython SDK v4、JavaScript / TypeScript SDK v5、または OpenTelemetry で x-langfuse-ingestion-version: 4 を付けることが推奨されます。それ以外の場合、新 UI では最大おおよそ 10 分ほど表示が遅れることがあります。
Langfuse v4 に向けた、根本からの考え方#
ここから先で押さえておきたいのは、v4 は速くなるだけではない、という点です。どの単位をデータの主語にするか、どう保存し・どう問い合わせるかという前提を、いまのLLMの使われ方に合わせて揃え直しています。
エージェントや複数ステップのパイプラインが一般化するにつれ、1 回のユーザー操作に紐づく Observation の数は桁違いに増えます。Trace の中に処理がたくさん入る世界では、「Trace を開いてから中を探す」だけでは運用もクエリも窮屈になりやすい、というのが背景にあります。
クラウド上の製品体験は公式ドキュメント Langfuse Cloud: Fast Preview (v4) で説明されています。クライアント側では、Observation 中心にしたデータモデルに合わせて Python SDK v4 と JavaScript / TypeScript SDK v5 が同じ方向に更新されています。
1. Observations-first: まず「処理単位」からたどれるようにする#
v3 までの体験に慣れていると、一覧や探索の入口が Trace に寄りがちです。中身を開いて初めて、LLM 呼び出しやツール実行といったいま調べたい処理にたどり着く、という読み方になります。
v4 の Observations-first は、この順序をひっくり返すイメージです。「どの Trace のどこかが遅いか」ではなく、「どの LLM 呼び出しが遅いか」「どのツールが失敗しているか」のように、日常の問いの起点を Observation に置きます。エージェント的なアプリでは 1 Trace にかなりの数の処理がぶら下がり得るので、最初から処理単位で絞り込めることが重要、という整理です。
評価では、Trace 全体だけでなく Observation ごとに LLM-as-a-judge などを回せるようになる流れも、v4 とセットで押し上げられている話題のひとつです。Observation ごとの評価については弊社ブログ Langfuse の Observation レベル評価:「どのステップが悪いのか」をスコアで特定できるようになった をご覧ください。
画面の使い方や保存データの詳細は、公式ドキュメント Explore Observations in v4 をご覧ください。
2. データの置き方を変えて、画面や API の表示を速くする#
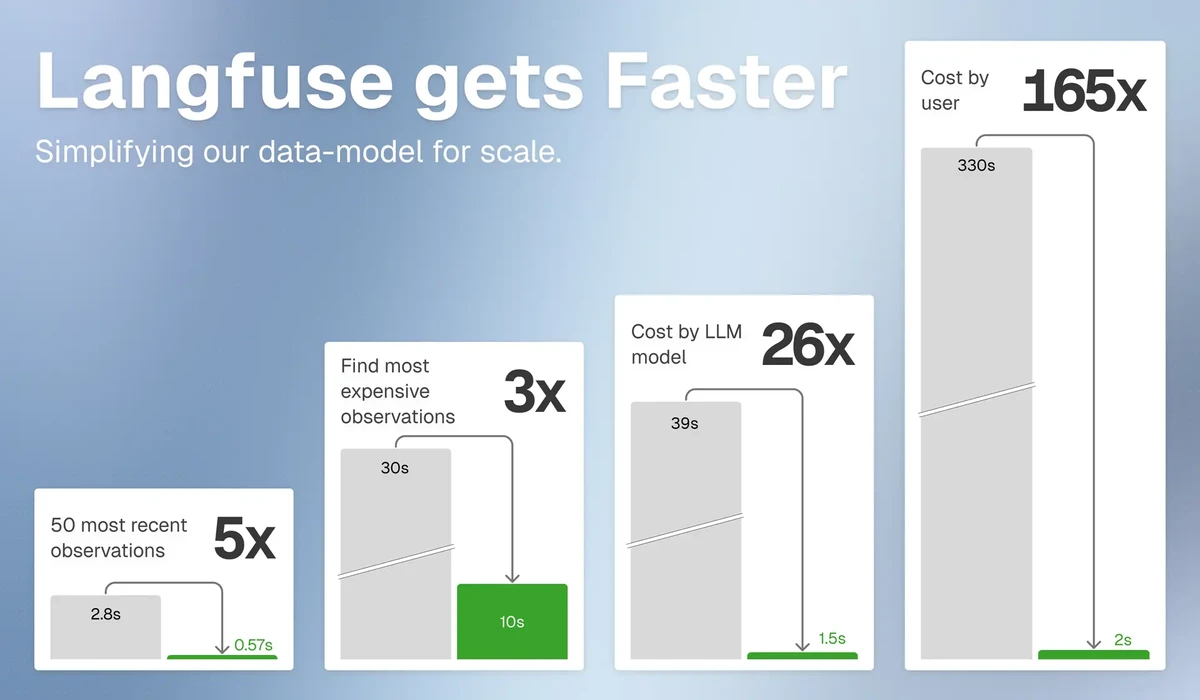
結論から言うと、v4 では一覧・ダッシュボード・公開 API などが速くなる方向です。「すでに速い」という前提ではなく、これから大きなデータ量でも待ち時間を抑えやすくする、という認識が正しいです。
Langfuse 公式ブログの Simplifying Langfuse for Scale(2026-03-10) では、Observation を中心にしたテーブル構成に寄せることで、速度改善しているという説明が丁寧にされています。大規模プロジェクトでは、ダッシュボードの読み込みが桁違いに改善した、といった記述もあります。
具体的には、Trace 用と Observation 用だった 2 つのテーブルを、1 つにまとめています。テーブルを分けたまま結び付ける「join」負担を減らします。

3. Langfuse API v2 がデフォルト API に#
Langfuse の公開 API には、いま主に二つの世代があります。古い形が v1、新しい形が v2 とざっくり理解できます。v4 の流れでは、Observation・Scoreまわりでこの v2 がデフォルトの API になり、SDK からも v2 を普通に呼ぶ名前がメインに揃います。v1 に相当する呼び出しは legacy 側にまとめられます。名前やパスを変えたことが目的ではなく、「いま推奨されるのは v2」という分かりやすい入口に寄せている、というイメージです。
例えば、Observations API v2 は、返す列の絞り込みやカーソル方式のページ送りなど、v1 より大量データでも負荷と待ち時間を抑えやすい問い合わせに作り替えられています。
4. SDK も Langfuse v4 に合わせる#
Langfuse サーバー側、つまり Langfuse の本体プログラムが Observation 中心のデータモデルに寄せられた以上、アプリ側から送る SDK 側も Trace を都度まとめて更新するだけの書き方では、保存されるデータとしっくりきません。そのため Python v4 と JS/TS v5 は、言語が違ってもLangfuse v4の方針に似た仕様に揃っています。
Trace共通属性は「Trace だけ」ではなく「子にも載せる」#
user_id / session_id / metadata / tags などは、Trace 行にだけあるのではなく、配下のObservation にも伝わるのが前提です。Python では propagate_attributes() のようなコンテキストマネージャ、JS/TS では propagateAttributes() のようなコールバックでスコープを切る メソッド として表現されます。言語が違っても、「この範囲で作られる Observation に、Trace共通属性を載せる」という意味は共通です。
Trace への一括更新から、役割を分ける#
以前の Trace をまとめて更新するメソッド(Python の update_current_trace()、JS/TS の updateActiveTrace() など)は、いろいろな種類の情報が一塊になっていました。v4 / v5 ではこれを分け、Trace共通属性は propagate、Trace 全体の入出力や公開状態は別のメソッドにします。
新しいコードでの推奨は、「Trace の入出力に相当する情報」を、親を持たないルートの Observation の入出力として載せることです。通常、Trace にはそうしたルートがひとつあり、そこに載せた入出力が、画面や連携でいう Trace の入出力として扱われるイメージに寄せます。Trace 専用にまとめて入出力を書き込む API は、互換のため残っていますが、主に従来の Trace 単位の LLM-as-a-judge 向けで、新規はルート Observation を使う説明になっています。
Spanの作成を「Observation」から開始にする#
今まではSpan と Generation という名前で別々のメソッドで増やす方針でした。これからは、Observation という共通の名前で開始し、observation typeを種別を引数で表す方向です(Python の start_observation / start_as_current_observation、JS/TS の startObservation / startActiveObservation など)。クライアント側でも主語が Observation だと分かる形にしている、という理解で十分です。
OpenTelemetry 経由の span#
OpenTelemetry 経由のspanについて、以前はほぼすべての span を送る前提に近い挙動があり、HTTP や DB などインフラ寄りの span が多いとトレースがノイズだらけになりがちでした。Python v4 / JS/TS v5 では、デフォルトで LLM / GenAI に近い span を中心に送るフィルタが入り、まずは見たいものが見える方向の初期設定になっています。OpenTelemetry経由の spanの制御については、別稿の A2A × ADKの"観測粒度"を設計する - Langfuse & Cloud Trace でトレース構造を可視化 - でも触れています。
SDK の破壊的変更の一覧や置き換え手順は、次を参照してください。
おわりに#
Langfuse v4 は、速度が上がるだけの話ではありません。Observation を中心にデータの持ち方と照会の前提を組み替え、そのうえで UI・公開 API・評価が同じ土台を共有する、という横断的な更新です。Trace の中に処理が密集する使われ方に合わせ、一覧や分析が Observation から直接たどれるようになる、という流れとセットで理解すると全体像がつかみやすいです。Langfuse v4 に合わせ、SDK も Observation 中心モデルにクライアントを合わせるバージョンアップがありました。
さらに詳しく知りたい方は、次のWebページを参照してください。