こんにちは。ガオ株式会社の黒澤です。LangfuseのCloud版にて、Experiments が独立した機能としてメニューから選択できるようになりました。本記事では、Experimentsでどのようなことができるのかということを、変更点や動作確認を交えて解説します。
結論を先に述べると、LangfuseのExperimentsはDataset配下の機能から、独立した評価実行の管理単位へ変わりました。SDK経由ではDatasetを作らずにローカルデータを流して実験できます。ただし、Prompt ExperimentsのUI実行では現時点でもDatasetの選択が前提であり、新しいExperiments体験はLangfuse Cloud / Fast Preview限定です。
想定読者
- Langfuse を使ってプロンプト評価・実験を行っている方
- LLMOps ツールの最新動向を追っている方
この記事でわかること
- Experiments が Dataset から独立した背景と変更内容
- UI と SDK で Dataset が必要かどうかの違い
- Self-hosted 環境での利用可否と今後の見通し
変更のきっかけと目的#
従来の Langfuse では、Experiment は必ず Dataset の中に紐付いた存在でした。Dataset なしには Experiments を作成できず、UI 上でも Experiments 専用のメニューは存在しませんでした。
この構造が実験ワークフローの柔軟性を制限していたため、2026年4月のアップデート「Experiments as a First-Class Concept 」(チェンジログ公開: 2026-04-13、v3.168.0 リリース: 2026-04-17)で、Experiments が Dataset と同列の独立した概念として再設計されました。
前提・スコープ#
この記事で扱うこと
- Experiments メニューの UI 変更
- SDK(Python)を使った Dataset なしでの Experiments 実行方法
この記事で扱わないこと
- LLM-as-a-judge や evaluator の設定方法
- スコアリング(採点)の詳細な設定
検証環境
- Langfuse JP Cloud(jp.cloud.langfuse.com)
- Fast Preview mode(v4 Beta)を有効化した状態
本題#
変更前:Experiments は Dataset の「中」にあった#
変更前の Experiments を使う流れは次の通りでした。
- 比較用のテストケースを Dataset として作成する
- Dataset を開き、その中で Experiments を実行する
- 結果を比較する
Experiments は Dataset に紐付いた存在で、UI 上でも Experiments 専用のメニューはありませんでした。
変更後:Experiments が独立したメニューに昇格#
今回のアップデートで、UI の左サイドバー Evaluation セクションに、Datasets と並んで Experiments (Beta) という独立したメニューが追加されました。
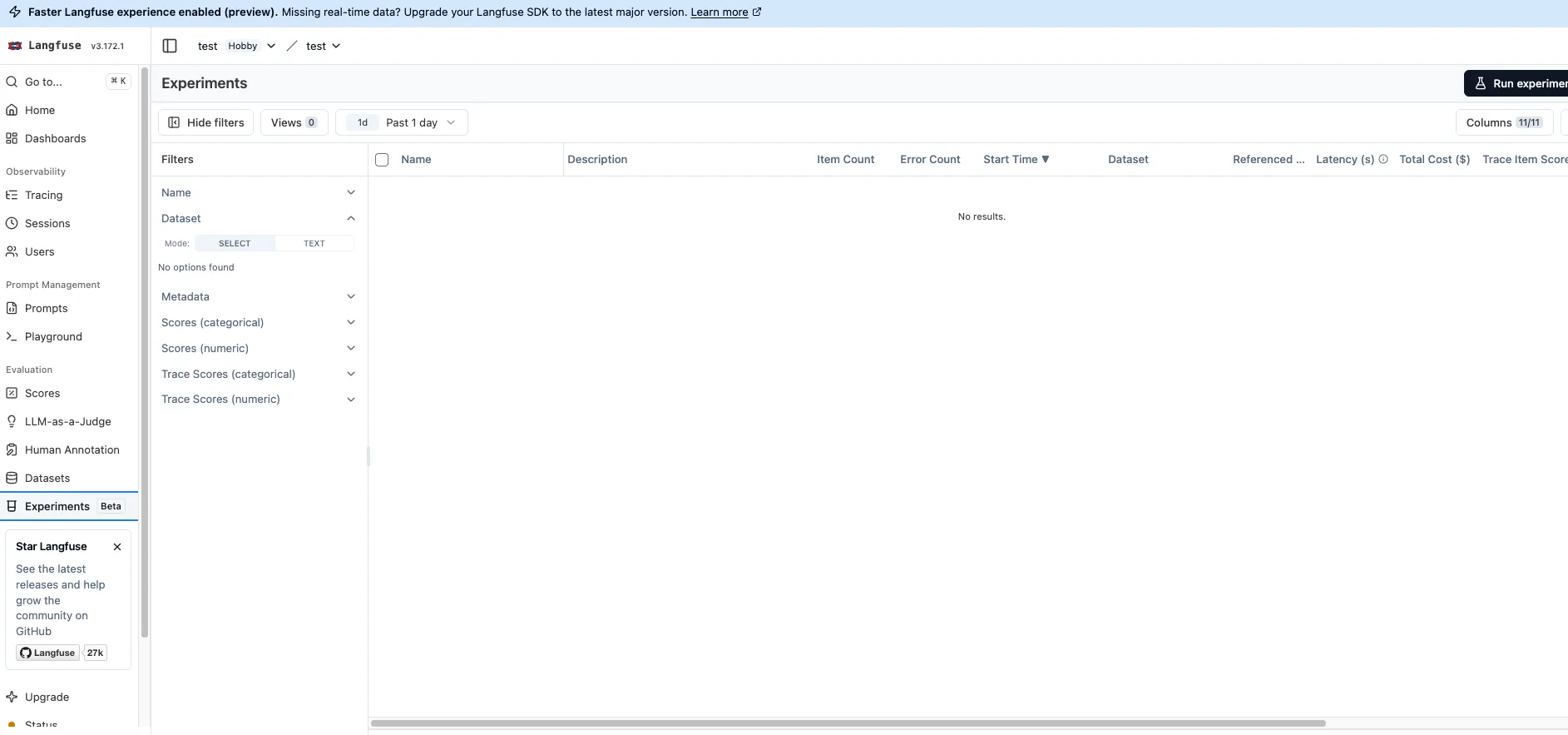
すべての Experiments を一覧で管理できます。
Experiments とは#
Experiments は、プロンプトやモデルを変えたときの結果をコスト・レイテンシ・スコアで横並び比較できる評価機能です。「プロンプト v1 と v2 を同じ10問にかけたとき、どちらの精度が高かったか」を数値で把握するために使います。
今回の変更により、以前は必須だった Dataset(テストケースの管理場所)を用意しなくても SDK 経由で Experiments を実行できるようになりました。UI(ウィザード)では引き続き Dataset の選択が必要です。手元のデータを SDK から直接流せるため、評価を始めるまでのステップが減っています。Dataset はデータの管理場所、Experiments は評価の実行記録、という概念が分離されたのが今回の本質的な変化です。
Playground との違い#
Experiments と混同されやすいのが Playground(プロンプト管理画面のインタラクティブなテスト機能)です。両者の位置付けを整理しておきます。
| Playground | Experiments | |
|---|---|---|
| 位置 | Prompt Management | Evaluation |
| 目的 | プロンプトを試す・開発する | 性能を測る・比較する |
| 入力 | 1件ずつ手動 | 複数件まとめて実行 |
| 結果の記録 | 残らない | 蓄積して比較できる |
「Playground で感触をつかんで、Experiments で定量的に確かめる」という流れが想定されたワークフローです。
Dataset の扱い:UI では引き続き必須、SDK では任意#
SDK を使えば、Dataset なしで Experiments を実行し、その結果を Experiments 一覧で確認できるようになりました。ただし、UI と SDK で挙動が異なります。
UI(ウィザード): Dataset の選択が引き続き必須です。選択せずに実行しようとするとバリデーションエラーになります。
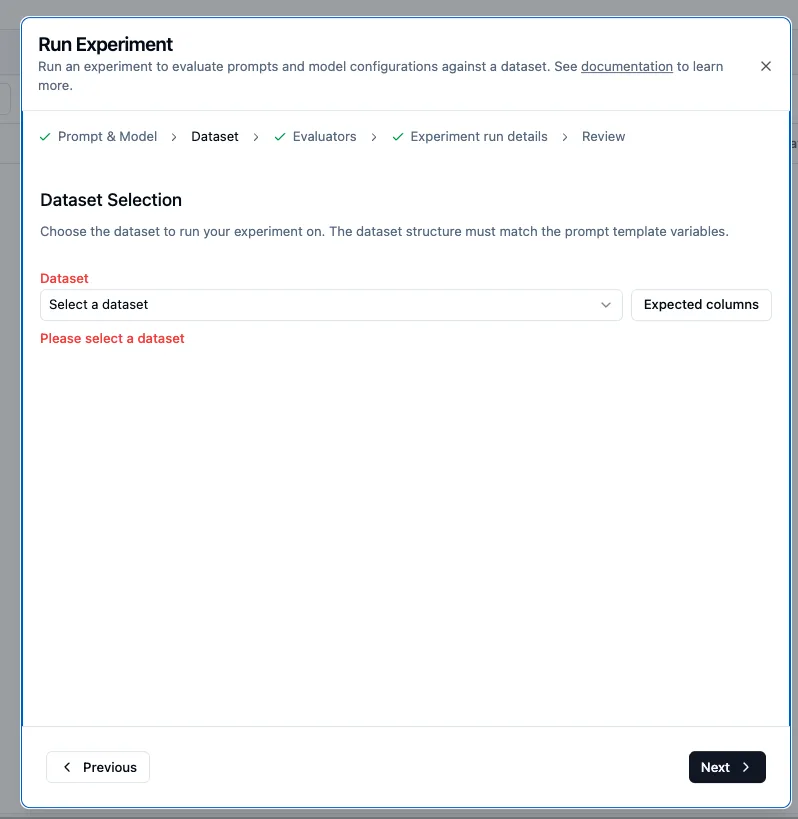
SDK(辞書リスト形式): Dataset なしでローカルデータを直接渡して Experiments を実行できます。
run_experiment() は Langfuse Python SDK v3.4.0 から利用できます。本記事のコード例は v4 系の get_client() を使用しています。v4 は SDK のエントリポイントが刷新されており、従来の Langfuse() コンストラクタから get_client() への移行が推奨されています(pip install "langfuse>=4")。
# 事前に LANGFUSE_PUBLIC_KEY、LANGFUSE_SECRET_KEY、LANGFUSE_HOST を環境変数に設定しておきます
from langfuse import get_client
langfuse = get_client()
def my_task(*, item, **kwargs):
return my_llm_call(item["input"]["question"])
result = langfuse.run_experiment(
name="プロンプト改善テスト",
data=[
{"input": {"question": "日本の首都はどこですか?"}},
{"input": {"question": "富士山の高さは?"}},
],
task=my_task,
)注意: ローカルデータを使った SDK 実行では、Langfuse 上に trace やスコアは記録されますが、Dataset Run は作成されません。Dataset Run として結果を比較したい場合は、Langfuse 上の Dataset を使う必要があります。
Dataset あり(UI 実行)と Dataset なし(SDK 実行)の Experiments が、同じ一覧画面で並んで管理されます。
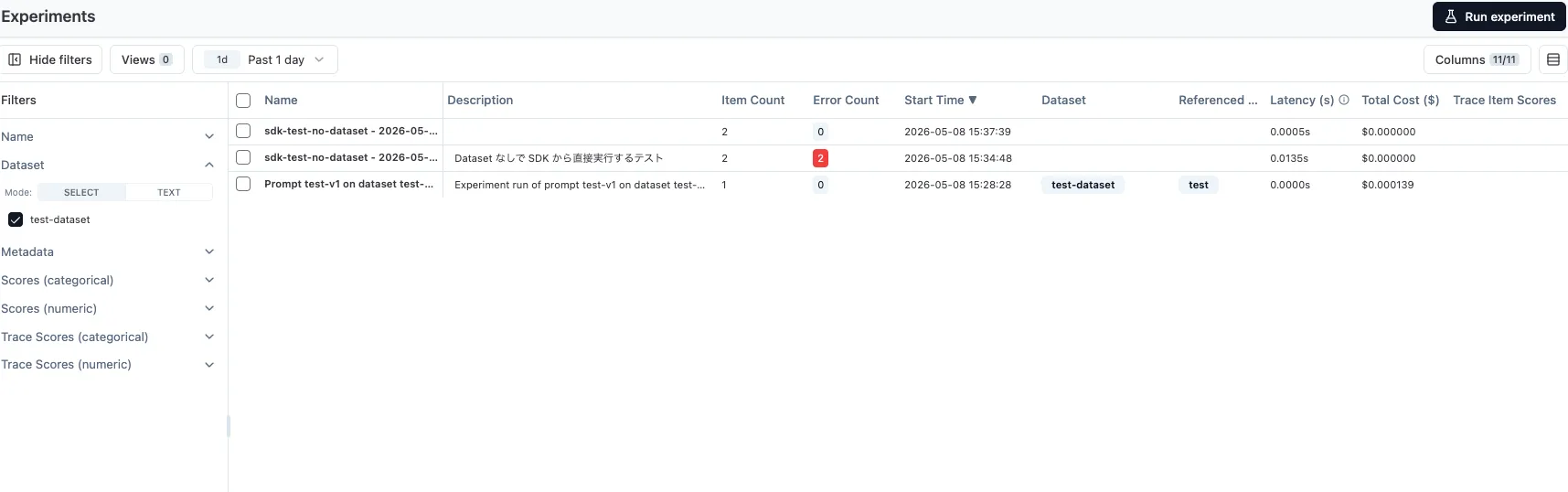
上2行は Dataset 列が空(SDK 経由)、3行目は Dataset 列に「test-dataset」と表示されています(UI 経由)。一覧ではコスト・レイテンシ・スコアを横並びで確認できます。
なお、公式チェンジログでは本番トレースも Experiments のデータソースとして扱える方向性が示されています。ただし、今回確認した UI では Dataset アイテム追加画面の一括選択機能「Select Traces」が現時点では Coming soon でした。現時点で本番トレースを活用するには、個々のトレース詳細画面から Dataset アイテムとして追加する方法が使えます。
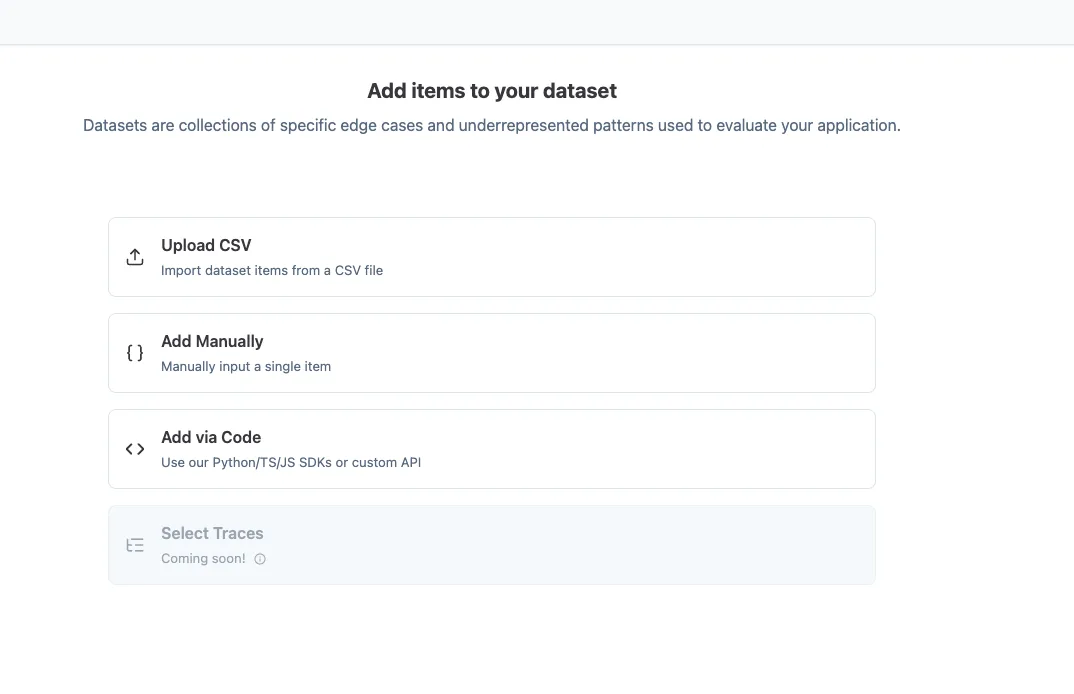
個々のトレース詳細画面から Dataset アイテムとして追加する方法は既に使えますが、一括選択は今後のアップデートを待つ必要があります。
ユースケース#
この変更で何が嬉しいのか、実務の文脈で整理します。
評価を小さく始めて、必要なものだけ Dataset 化できる — 従来は「まず Dataset を作る」という準備が評価の入口でした。この制約がなくなったことで、手元に試したい入力が数件あればすぐ
run_experiment()に渡して結果を確認できます。良いテストセットだとわかったものだけ Dataset として整備する、という順序で進められるため、評価を始めるまでのコストが大きく下がります。テストケースをコードで管理できる — SDK にローカルデータを渡す形式になるため、テストケースをコードリポジトリに置いてバージョン管理できます。Langfuse UI 上でマスターの Dataset を都度作成・更新しなくてよく、プロンプト変更の PR にテストケースを一緒に含めてレビューできます。環境(dev/stg/prd)をまたいでも同じテストセットが使えます。
CI/CD に評価を組み込める — テストデータがコード側にあるため、プロンプト変更を含む PR ごとに
run_experiment()を自動実行し、正答率・コスト・レイテンシが閾値を下回ったらレビューを止める、という構成が組めます。LLM の品質チェックを、ユニットテストと同じパイプラインで回せます。Experiments の横断管理 — Dataset 経由・SDK 経由のどちらで実行した Experiments も同じ一覧画面で管理できます。複数の Dataset にまたがる実験結果をコスト・レイテンシ・スコアで横並び比較できます。
注意点:現時点は Langfuse Cloud 限定#
この独立した Experiments メニューと Fast Preview 上の新しい Experiments 体験は現時点で Langfuse Cloud 専用 です。Self-hosted 環境では利用できません。
コードレベルで Cloud フラグで制御されており(PR #13131 )、設定による回避手段はありません。Self-hosted 環境で同様の Experiments を行う場合は、引き続き従来の Dataset 機能を使ってください。
Cloud ユーザーが有効化する方法:
- 左下の「Fast Preview mode(v4 Beta)」をオンにする
- 2026-04-14 以降に作成した組織はデフォルトで有効
Self-hosted への展開時期は未定です。なお、GitHub Discussion #12518 では v4 アーキテクチャ全体の OSS 展開について議論されており、Experiments 機能の動向も合わせて追えます。
まとめ#
| 比較軸 | 変更前 | 変更後 |
|---|---|---|
| Experiments の UI 位置 | Dataset の内側 | 独立したメニュー |
| SDK での Dataset | 必須 | 任意(辞書リストで直接渡せる) |
| UI での Dataset | 必須 | 引き続き必須 |
| 本番トレースの一括利用 | 不可 | Coming soon |
| Self-hosted 対応 | ○(Dataset 機能) | 時期未定 |
一見するとUIの配置変更に見えますが、実際には「Datasetが主、Experimentが従」という関係から「Datasetはデータ、Experimentは実行記録」という関係へ整理された点が重要です。「評価を始めるには Dataset が必要」という制約が取り除かれ、評価を小さく始めて必要なものだけを Dataset 化していけます。ただし現時点では Langfuse Cloud 限定のため、Self-hosted 環境では引き続き Dataset 機能を使いましょう。
参考リンク
- チェンジログ: https://langfuse.com/changelog/2026-04-13-experiments-rebuild
- v4 ドキュメント: https://langfuse.com/docs/v4
- v4 OSS 展開の議論: https://github.com/orgs/langfuse/discussions/12518
関連記事(GAO ブログ)