ガオ株式会社では、社内およびグループ企業間の業務で自律型エージェント Hermes Agent (NousResearch/hermes-agent) の活用を進めています。
エージェントが Tool を呼び出しながら自律的に業務を進めるようになると、LLM API call 単位のログだけでは挙動を追いきれません。さらに自律型エージェントの場合、人手が介在せず判断と実行が連続して走るため、観測性 — 後から誰が何を要求し、エージェントが何を判断し、どの Tool をどう実行したかを追える状態 — が、従来以上にガバナンスや内部統制の観点で重要になります。
本記事では、Hermes Agent v0.12 系以降に同梱されている Langfuse observability プラグインを self-hosted Langfuse に接続し、エージェントの挙動を 3 段の観点 (ターン / LLM 呼び出し / Tool 実行) で追跡する構成と、運用上の注意点を紹介します。
TL;DR#
- エージェントの観測は、LLM 呼び出し単体ではなく「推論と Tool 実行のループ全体 (ターン)」で追跡する必要がある
- Hermes Agent 組み込みの Langfuse プラグインを利用すると、ターン / LLM call / Tool call の階層構造を持つ trace を Langfuse に送信できる
- セッション ID が Langfuse 側に伝搬されるため、Slack や Cron 経由の複数ターンにまたがるやり取りも
Sessionsビューで一覧できる - Tool の入出力には機密情報が含まれ得るため、本番運用ではアクセス制御、保持期間、マスキング方針の設計が必須
LLM 呼び出し単位の観測だけでは足りない場面#
これまでの LLM アプリケーション運用では、API 呼び出し単位の観測が一般的でした。しかし、自律型エージェントを業務に組み込むにつれて、これだけでは挙動を説明しきれない場面が増えてきます。
- LLM 呼び出しの記録だけでは、
terminal/web/file/ 検索系などの Tool 実行時の入出力が Langfuse 上から確認できない - 「ユーザー発話 → 推論 → Tool 実行 → 再推論 → 応答」という 1 ターンを 1 つの trace にまとめる仕組みが標準では用意されない
- 複数ターンの会話 (セッション) を Langfuse の Sessions ビューに紐づけるには、セッションIDを trace に乗せる別途の仕組みが必要になる
ガバナンスや証跡の観点からエージェントの挙動を説明可能にするには、LLM 呼び出しよりも一段上の粒度で観測を残す必要があります。
Hermes Langfuse プラグインで記録できるもの#
Hermes Agent には v0.12 系以降、Langfuse observability プラグインが同梱されています。このプラグインは Hermes プロセス本体にフック (hook) として動作し、以下の 3 種類の観測単位を Langfuse に送信します。
| 観測単位 | Langfuse 側の span 名 | 内容 |
|---|---|---|
| Hermes turn | Hermes turn | ユーザー発話に対するエージェントの 1 ターン全体 |
| LLM call | LLM call N | そのターン中の N 回目の LLM 呼び出し |
| Tool call | Tool: <name> | LLM が要求した Tool 実行 1 回 |
ターン全体を 1 つの trace に集約#
Hermes turn が trace の root span となり、そのターン内で発生した LLM call と Tool call が同列の子 span として並びます。
Hermes turn
├── LLM call 1
├── Tool: terminal
├── LLM call 2
├── Tool: web_browse
└── LLM call 3LLM のログと Tool のログを別々に突き合わせる必要がなくなり、Langfuse 上で「どの Tool が、どの入力で、どういう結果を返したか」を 1 つの trace から辿れます。
実例: Slack からのリクエストと Langfuse trace#
実際の運用例を 1 つ示します。Slack で Hermes に「この週末で Hermes Agent に日本語で言及している人を X で探してみて」と依頼したターンです。
Hermes は X の検索 Tool (x_search) を 3 回呼び分けながら情報を収集し、最終的に要約を Slack へ返しています。同じターンを Langfuse 上で開くと、Hermes turn を root として LLM call と Tool call が交互に並ぶ trace になっていることがわかります。
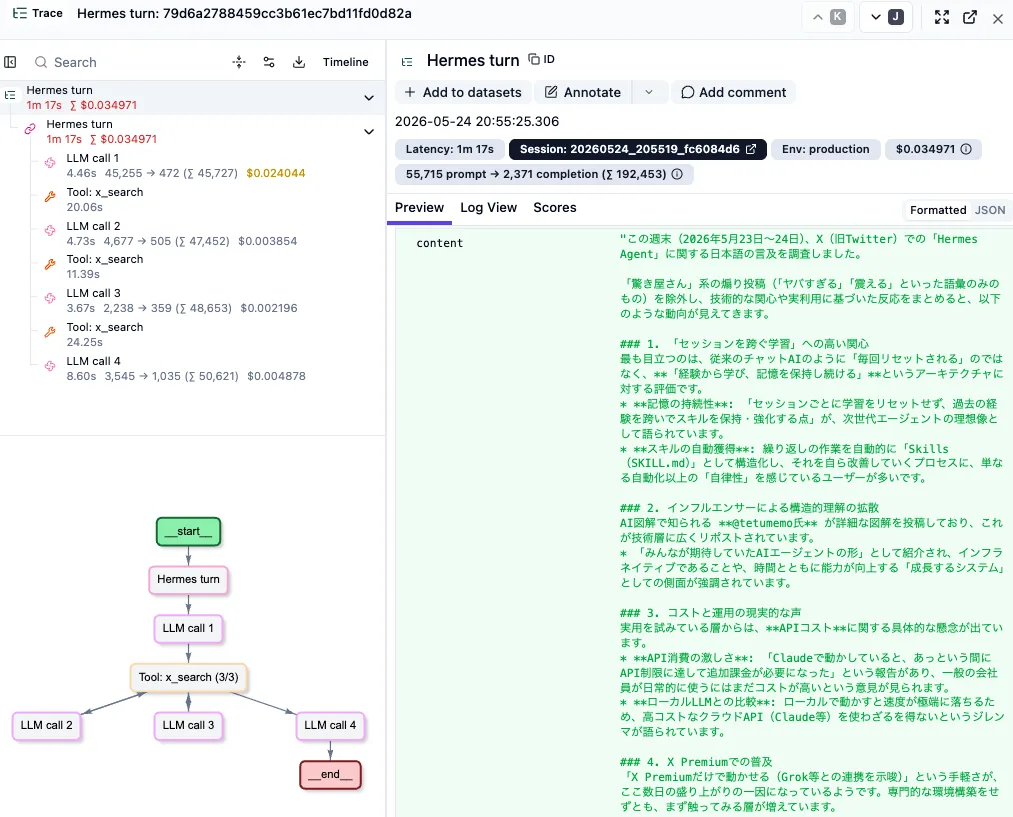
LLM call 1 (4.46s) → x_search (20.06s) → LLM call 2 (4.73s) → x_search (11.39s) → LLM call 3 (3.67s) → x_search (24.25s) → LLM call 4 (8.60s) と、推論と Tool 実行のループ全体が 1 つの trace にまとまっています。各 Tool call の input / output や所要時間も span 単位で確認でき、ターン全体の latency (1m 17s)、消費トークン (55,715 prompt → 2,371 completion)、コスト ($0.034971) も同じ画面に集約されています。
セッションIDによる複数ターンの集約#
プラグインは Hermes 側のセッションIDを Langfuse 側へ伝搬します。Langfuse の Sessions ビュー で、同じセッションから生まれた複数のターンをまとめて確認できます。Slack 上の継続的なやり取りや、Cron 経由で発火する一連のジョブを、セッション単位で追跡する用途に向いています。
Tool 入出力の記録と sanitize#
Tool の入出力は、プラグイン側で sanitize されたうえで span の input / output に格納されます。ただし、read_file のように大きな payload は要約され、各フィールドも HERMES_LANGFUSE_MAX_CHARS (デフォルト 12000) に応じて切り詰められます。実行結果が常に完全な形で保存されるわけではない点には留意が必要です。
usage 情報#
usage 情報も Hermes 側で正規化されて送信されるため、Langfuse のダッシュボードで input / output / cache_read / cache_write / reasoning tokens など、種類別のトークン消費が確認できます。コスト(USD 換算)の算出には、モデル名の指定方法と Langfuse 側の pricing 設定が関係するため、運用上の注意点として後述します。
当社におけるアーキテクチャと検証環境#
ここからは、当社で実際に運用・検証している構成を紹介します。
検証環境#
| コンポーネント | バージョン / 構成 |
|---|---|
| Hermes Agent | v0.14 系 (observability/langfuse plugin 1.0.0) |
| Langfuse SDK | 4.x |
| Langfuse | self-hosted (Google Cloud 上) |
| LiteLLM Proxy | 検証時点の安定版 |
| Python | 3.11 |
| LLM バックエンド | Vertex AI 上の Gemini 系モデル (Gemini 3 Flash Preview など) |
Langfuse プラグインは Hermes Agent v0.12 系で初導入されました。本稿は v0.14 系で検証しており、Tool output や trace I/O 周りの挙動は実環境で確認しています。
構成図#
Slack ──► Hermes Agent ──► LiteLLM Proxy ──► Vertex AI (Gemini 3 Flash Preview ほか)
│
└─ (ネイティブ Langfuse プラグイン) ──► self-hosted Langfuse
Hermes turn (root) ─┬─ LLM call N
└─ Tool: <name>
セッションIDで Sessions ビューに集約主な構成要素は以下のとおりです。
- Hermes Agent: 常駐プロセスとして稼働
- 入出力: Slack Socket Mode で受け付け。
@mention/ DM / Cron 経由で発火 - LLM バックエンド: 応答速度とコストパフォーマンスを重視し、現在は Gemini 3 Flash Preview (
gemini-3-flash-preview) をデフォルトに採用。組織課金で運用するため、管理対象の Google Cloud プロジェクト経由でアクセス - LLM 接続レイヤー: LiteLLM Proxy。Hermes の OpenAI 互換クライアントを Vertex AI に橋渡し
- 観測性: self-hosted Langfuse
Hermes には Google / Gemini 向けのプロバイダもあります。一方、当社のように Vertex AI の管理対象 Google Cloud プロジェクト経由で組織課金やモデルルーティングを集約したい構成では、本稿の検証時点では LiteLLM Proxy を OpenAI 互換ブリッジとして使うのが現実的でした。モデルエイリアス、モデル間 fallback、OpenAI 非互換パラメータの吸収といった運用上の調整も、LiteLLM 側で扱っています。
本記事で扱う観測性の構成はこの LiteLLM の役割とは独立しており、LiteLLM は LLM 接続の責務、Hermes Agent 側のプラグインは観測の責務 という分担です。
導入手順#
self-hosted Langfuse がすでにある前提です。
1. Langfuse SDK のインストール#
プラグインは SDK を別途必要とします (Hermes Agent の必須依存には含まれていません)。Hermes の venv に導入します。
uv pip install --python ~/.hermes/hermes-agent/venv/bin/python "langfuse==4.*"2. 認証情報を .env に追加#
# ~/.hermes/.env
HERMES_LANGFUSE_PUBLIC_KEY=pk-lf-xxxxxxxx
HERMES_LANGFUSE_SECRET_KEY=sk-lf-xxxxxxxx
HERMES_LANGFUSE_BASE_URL=https://langfuse.example.com # self-hosted の URL に置換
HERMES_LANGFUSE_ENV=production3. プラグインを有効化#
hermes plugins enable observability/langfuse
hermes plugins list # observability/langfuse が enabled 表記になることを確認4. Hermes プロセスを再起動#
Hermes を再起動してプラグインを読み込ませます。
動作確認#
Hermes に 1 ターン会話を投げて、Langfuse 上で以下を確認します。
Hermes turnを root とする trace が新たに作成される- 1 つの turn 内に複数の
LLM callspan が含まれる (Tool ループが回った turn の場合) - Tool 実行があった turn では
Tool: <name>span が子として作成される - Tool input / output が想定どおり記録される (記録すべきでない情報が含まれていないかも確認)
- Sessions ビューで同じセッションIDの turn がまとまっている
切り替え後は、LLM call と Tool call の入出力を同じ画面で追えるようになります。エージェントのデバッグや証跡確認の起点も、Langfuse に集約できます。
運用上の注意点#
Tool 入出力と機密情報#
Tool の入出力を span として残せることはデバッグや証跡確認の大きな利点です。一方、これは Tool に流れた情報が 意図せず Langfuse 上に永続化されるリスク があるということでもあります。プラグイン側で sanitize や切り詰めが行われる場合でも、何が送信されるかを前提に運用設計する必要があります。
エージェントの Tool には、運用上次のような情報が流れ込みます。
- Slack の会話内容 (private channel や DM 含む)
- 社内ドキュメントの断片
terminal系 Tool の標準出力- URL や query parameter (一部に token を含む場合あり)
- 外部 API のレスポンス (個人情報を含むこともある)
本番運用前に、以下を整理しておくことを推奨します。
- Langfuse 側のアクセス制御 (RBAC) を最小権限に絞る
- trace の保持期間 (retention) を運用方針に合わせて設定する
- Tool ごとに「観測対象にしてよいか」を切り分ける。secret や token を返す可能性のある Tool については、プラグイン側の payload マスキングや切り詰めを検討する
- 検証用と本番用で Langfuse の project を分ける
- 社内データの取り扱いポリシーと整合させる
「観測できる」と「観測してよい」は別問題です。可視化の前にデータ取り扱いの設計を明確にしておくことが重要です。
コスト集計とモデル名の扱い#
Langfuse のダッシュボードに表示されるコスト (USD 換算) の算出には、2 つのパターンがあります。
- Hermes プラグインが cost を送るパターン: プラグイン内部の pricing 表 (
agent.usage_pricing) からエントリが引ければ、cost_detailsを組み立てて Langfuse に attach する - Langfuse 側で自動算出されるパターン: プラグインの pricing 表にエントリがない (Vertex AI の preview 系モデルなど) 場合、
cost_detailsは送られない。Langfuse は trace に乗っているmodelとusage_detailsから、登録済み model definition の pricing を使ってコストを推論する
Hermes Langfuse プラグインは Hermes が LLM 呼び出し時に指定した model 名 をそのまま model フィールドに転記します。LiteLLM Proxy のエイリアスを Hermes 側のモデル設定にしている構成では、その文字列が Langfuse 側にも記録されます。
当社では LiteLLM のエイリアスを Vertex AI 標準モデル名 (gemini-3-flash-preview など) に揃えました。これにより Langfuse 側の model definition による自動算出が利用できるようになっています。エイリアスを独自命名のまま運用する場合は、Langfuse 側で対象モデルに custom pricing を登録する方法もあります。
SDK 依存関係#
langfuse SDK は Hermes Agent 本体の必須依存には含まれていないため、Hermes の venv に手動で導入する必要があります。Hermes Agent のアップグレード後は、SDK が引き続き利用可能か確認しておくと安全です。また、Langfuse SDK v4 は OpenTelemetry 系パッケージに依存し、この経路で入る opentelemetry-proto が protobuf<7.0,>=5.0 を要求します。他の依存が protobuf 4 系や 7 系を固定している環境では resolver 競合の可能性があるため、SDK 導入後はインストールログを確認しておくと安全です。
観測コストとペイロードサイズ#
LLM call だけでなく Tool call も trace に含まれるため、Langfuse に送信される span 数と payload サイズは LLM call 単位の観測と比べて増えます。特に terminal や file 系 Tool の出力は大きくなりやすく、Cron 経由の定期ジョブが多い構成では送信量に注意が必要です。長大な output の切り詰め、重要度に応じた sampling、Langfuse 側の保持期間設計を組み合わせるのが現実的な対応になります。
二重記録の回避#
LiteLLM Proxy 側で litellm_settings.callbacks: ["langfuse_otel"] を有効化しているなど、別経路でも Langfuse へ trace を送る仕掛けがある場合、同じ LLM 呼び出しが二重に記録される可能性があります。Hermes プラグイン側に観測を寄せる構成では、LiteLLM 側の callback は停止する必要があります。
ロールバック#
問題が発生した場合は、プラグインを無効化して Hermes を再起動すれば導入前の状態に戻せます。
hermes plugins disable observability/langfuse変更点は .env とプラグインの enable / disable に限られるため、切り戻しは比較的容易です。
導入して得られたもの#
導入後、エージェント運用の調査や検証の起点を Langfuse に寄せられるようになりました。
- 調査時間の短縮: LLM call と Tool call を別々のログで突き合わせる必要が減り、Langfuse の trace を起点に turn 全体を辿れる
- Tool 利用の説明性向上: どの Tool が、どの入力で、どの結果を返したかを turn 単位で確認できる
- セッション単位の追跡: 複数ターンにまたがるやり取りを Sessions ビューから一覧できる
- 責務分離の明確化: LiteLLM は接続とルーティング、Hermes プラグインは観測、という分担に整理された
まとめ#
自律型エージェントを業務に組み込むほど、LLM API call 単位のログだけでは挙動を説明しきれず、ガバナンスや内部統制の観点で観測性の重要性が高まります。ユーザー発話、LLM の推論、Tool 実行、その結果を受けた再推論を同じ trace 上で追えることが、運用上の前提条件になってきます。
当社では、Hermes Agent のネイティブ Langfuse プラグインを有効化し、Hermes turn / LLM call / Tool call を同一 trace 上で確認できる構成を整備しました。LiteLLM は Vertex AI への接続とモデルルーティング、Hermes プラグインはエージェント実行時の観測、という責務分離により、運用上の見通しも改善しています。
一方で、Tool input / output を観測対象に含める場合、機密情報や個人情報の取り扱いには注意が必要です。本番運用では、Langfuse のアクセス制御、保持期間、マスキング、サンプリングをあわせて設計することを推奨します。
今後は、ここで構築した trace を起点に、応答時間やトークン消費量の SLO 管理、評価データセットへの接続にも取り組んでいく予定です。
ガオ株式会社では、生成 AI アプリケーション開発、LLMOps、エージェント基盤の設計・運用に取り組んでいます。Hermes Agent、Langfuse、LiteLLM などを用いた運用設計にご関心があれば、お問い合わせください。