こんにちは。ガオ株式会社の黒澤です。以前「LLMOpsとは? MLOpsとの違いや生成AIの評価について解説 」で LLMOps の全体像を整理しました。
本記事ではその続きとして、LLM Observability プラットフォームの Langfuse を用いた評価基盤の設計に焦点を当て、評価軸の洗い出しから Judge プロンプト設計・ゴールデンデータセット構築・メタ評価まで整理します。運用設計(誰が・いつ・どうやって)は続編で扱います。
想定読者#
- LLM アプリの評価基盤をこれから構築したい
- 評価基盤はあるが、Judge プロンプト設計やメタ評価まで整理できていない
※ 本記事は Langfuse を評価基盤として採用中/検討中の方を対象としています
本記事でわかること#
- 評価軸の洗い出し方と失敗パターンの把握方法
- 評価方法(LLM-as-a-Judge / Annotation Queues / Custom)の使い分け
- Judge プロンプトの設計原則
- ゴールデンデータセットの構築方法
- メタ評価の手順と精度検証の指標(Cohen’s Kappa・Confusion Matrix)
※ 本記事では、Judge と人間の評価を突合して精度を確認する作業を「メタ評価」と呼びます。
以前「LLMOpsとは? MLOpsとの違いや生成AIの評価について解説 」で解説した LLMOps の構成要素のうち、本記事は「自動評価・Human Annotation・データセット」の設計に絞ります。
全体フロー#
構築から改善サイクルまでの基本フローです。「本番投入」までが初期構築フェーズ、「運用」以降が本番投入後の改善サイクルです。本記事では A〜F(出発点・評価の仕組みづくり) を扱います。G〜J の運用設計は「LLMOps:評価基盤の運用編 — Langfuse 活用 」で解説します。
flowchart TD
A[A. プロンプトのルール分解
+ トレース目視確認] --> B[B. 評価方法の選定
+ Judge プロンプト設計]
B --> C[C. ゴールデンデータセット構築]
C --> D[D. メタ評価
Human Annotation で精度検証]
D --> E{E. 精度は十分?}
E -- No --> F[F. Judge プロンプト修正]
F --> D
E -- Yes --> G[G. 本番投入]
G --> H[H. 運用
自動評価 + スコア確認]
H --> I{I. 新しい失敗パターン
を発見?}
I -- No --> H
I -- Yes --> J[J. データセットに追加
+ Judge プロンプト改善]
J --> D
本文との対応:A = 出発点、B〜F = 評価の仕組みづくり のセクションで解説します。まず評価基盤でよくある 2 つの課題を整理した後、このフローの各ステップを順に解説します。
評価基盤でよくある 2 つの課題#
課題 1:構築時 — 何を基準に評価すればいいかわからない#
評価基盤を初めて作るとき、最初につまずくのが「何を評価すればいいかわからない」という問題です。システムプロンプトはあっても、それをどう評価軸に落とし込むか、どんな失敗パターンがあるかが見えていない状態からのスタートになります。
課題 2:運用時 — 評価基盤を作ったが活用できていない#
評価基盤を構築すること自体は、ツールの進化によって難しくなくなってきています。難しいのは、それを継続的に運用し、改善サイクルを回し続けることです。
運用フェーズでよく見かける課題:
- 評価の仕組みを設定したが、スコアを誰も見ていない
- スコアが低いトレースがあるが、次のアクションが決まっていない
- 機能が追加されたが、評価の仕組みが追従していない
- Judge プロンプトを変更したいが、変えると過去のスコアと比較できなくなる
出発点:まずこの 2 つから始める#
1. プロンプトのルールを分解して評価軸にする#
システムプロンプトには、LLM に守らせたいルールが書かれています。それを分解して、1 つずつ評価軸にします。
例:社内問い合わせチャットボットのシステムプロンプト
- ユーザーの質問に日本語で丁寧に回答してください
- 社内規程に関する質問には、必ずナレッジベース検索ツールを使ってください
- 制度の詳細については必ず公式情報を参照し、推測で回答しないでください→ 分解して評価軸にする:
| ルール | 評価軸 | 判定対象 | 判定方法 |
|---|---|---|---|
| 日本語で丁寧に | トーン | トレース全体の最終出力 | LLM-as-a-Judge |
| ナレッジベース検索ツールを使う | ツール使用の正しさ | ツール呼び出しの Observation | LLM-as-a-Judge |
| 推測で回答しない | 推測抑制(根拠遵守) | トレース全体の最終出力 | LLM-as-a-Judge |
評価軸によっては LLM-as-a-Judge に投げるまでもなく、プログラム判定(文字数チェック、JSON スキーマ検証、禁止ワードなど)で済むものもあります。
このようにシステムプロンプトを分解することで、評価軸の候補が洗い出せます。プロンプトに書かれていない暗黙ルール(出力長、禁止表現、ユーザー体験上のトーン等)は次のトレース目視で補完します。
2. トレースを 50 件ほど目視で確認して失敗パターンを把握する#
自動化の仕組みを作るのになぜ手作業?と思うかもしれませんが、想像ではなく実際のデータから「よくある失敗パターン」を抽出して評価基準を作るために、このプロセスが不可欠です。
実際のトレース(LLM への入力・処理・出力を記録したログ)を 1 つずつ確認し、OK / NG のパターンを見つけます。
見つかるパターンの例:
| パターン | 分類 | 具体例 |
|---|---|---|
| ツールを使わず推測で回答 | NG | 「たぶん 10 日以内だと思います」 |
| ツールを使い正確に回答 | OK | 「申請から 5 営業日以内です(社内規程参照)」 |
| 丁寧だが内容が間違い | NG | 廃止された制度を案内している |
50 件を目安にしているのは、1〜2 時間で目視できる量でありながら主要な失敗パターンが出揃いやすいという経験則からです。「こういうケースで失敗しやすい」というパターンが見えてきたら、それが評価基準の出発点になります。
評価の仕組みづくり#
出発点で洗い出した評価軸を、実際の評価として組み立てていきます。
評価方法の使い分け#
評価軸ごとに、適した評価方法は異なります。Langfuse では、すべての評価結果は Scores として統一的に記録され、ダッシュボードで傾向を追うことができます。
本セクションで使用する用語:
- Observation:トレース内の各処理ステップ(個々のツール呼び出しや LLM コールなど)
- Human Annotation:人間が Langfuse 上でトレースに対してスコアを付ける作業(Annotation Queues 経由で実施)
- Annotation Queues:対象トレースをキューに積み、担当者がスコアを付ける Langfuse のレビュー機能
- Evaluator:Langfuse 上で LLM-as-a-Judge を設定・実行する標準機能。モデル・Judge プロンプト・サンプリング率などを UI から指定できる
- Scores API:評価結果(スコア)を Langfuse に登録・取得するための API。自前の評価パイプラインや通知スクリプトから利用する
| 評価方法 | 計算処理が Langfuse 内で完結 | 適しているケース | 例 |
|---|---|---|---|
| LLM-as-a-Judge | Yes | テキストの質的判定、Observation 単位の判定 | トーン、事実性、ツール使用の正しさ |
| Annotation Queues | Yes | 人間のレビューが必要なケース | エッジケースの判断、Judge の精度検証(メタ評価) |
| Custom(API/SDK) | No(外部で計算し Scores API で結果を登録) | Langfuse のトレースデータだけでは判定できないもの、またはプログラムで機械的に判定できるもの(共通点:Langfuse 外で計算して Scores API で結果を登録する) | 外部 DB との突合、ビジネスロジックに基づく合否判定、プログラム判定(文字数・JSON スキーマ・禁止ワード等) |
ポイントは、LLM-as-a-Judge がトレース全体だけでなく Observation 単位でも評価できることです。たとえば「ナレッジベース検索ツールを使ったか」のようなチェックも、ツール呼び出しの Observation にフィルタをかけて Judge に判定させることで、Langfuse 上で完結できます。
なお、Observation 単位で評価する場合も、後述する 「1 つの失敗モードにフォーカス」の原則は崩さない でください(例:1 つの Observation に対して「ツールが正しく選ばれたか」と「出力の事実性」のような別軸の判定を 1 つの Judge プロンプトで同時に行わない)。Observation レベル評価の具体的な設定方法は「Langfuse の Observation レベル評価:「どのステップが悪いのか」をスコアで特定できるようになった 」を参照してください。
Custom 評価の具体的な実装は本記事では扱いません。以降は LLM-as-a-Judge を主軸に解説します(ただしプログラム判定は、運用編の「多層評価によるコスト削減」で Judge のコスト削減手段として再登場します)。
LLM-as-a-Judge:Judge プロンプトの設計原則#
出発点で見つけた NG パターンを、Judge プロンプトの採点基準に組み込みます。
設計原則として、Langfuse 公式ブログ「Automated Evaluations 」で紹介されている原則が参考になります。
| 原則 | 意味 | 例 |
|---|---|---|
| 1 つの失敗モードにフォーカス | 複数の失敗モード(評価軸)を 1 つのプロンプトに混ぜない | トーンと事実性を別々の Judge に分ける |
| Pass / Fail を明確に定義 | 何が OK で何が NG かを具体的に記述する | 「推測表現(“たぶん"“おそらく"等)を含む回答は Fail」 |
| 具体例を含める | Pass / Fail それぞれの実例を Judge プロンプトに入れる | OK 例・NG 例を 2〜3 件ずつ記載する |
※ Langfuse は Pass/Fail のほかに数値スコア(0〜1 など)やカテゴリラベルにも対応していますが、本記事では人間との突合がしやすい Pass/Fail(二値判定)に絞って解説します。
加えて、Judge プロンプトを設計する際は、「Fail を検出したら次に何をするか」をあらかじめ決めておくと運用につながります。具体的なアクション定義は運用編の「誰が・いつ・どうやって」で整理します。
ゴールデンデータセットを構築して評価の基準を固める#
評価を継続的に回すには、基準となるデータセット(ゴールデンデータセット)が必要です。出発点で目視確認した OK / NG パターンから、代表的なケースを 20〜50 件ほど選んで登録します(評価軸数 × 5〜10 件が目安。例:評価軸 3 本なら 15〜30 件。経験則ですが、少なすぎると Judge の挙動傾向が見えず、多すぎるとメンテが重くなるため、この範囲が扱いやすいです)。
- データセットの作成方法(UI・CSV・SDK)は「Langfuseデータセット構築ガイド:UI・CSV・SDKの徹底比較 」で詳しく解説しています
- トレース保存時にマスキング設定を適用済みなら、データセットにもマスク後のデータが入ります。生ログをデータセット化する場合は登録前にマスキングを検討してください(「Langfuseにおける個人情報(PII)のマスキング 」を参照)
このデータセットは以下の場面で使います:
- プロンプト変更時の回帰テスト — 変更前後で Experiments
を実行してスコアを比較します。
- Experiments の起動:Langfuse UI → Datasets → 対象データセット詳細 → 「Start Experiment」
- アプリ側のプロンプト・モデル変更:そのまま Experiments で比較可能
- Judge プロンプト自体の変更:Experiments はアプリ側の差分比較が主用途のため、同一データセットに対して旧 Judge と新 Judge をそれぞれ実行してスコアを並べる運用になる
- 比較手順は「LangfuseのExperiments Compare ViewのBaseline機能を解説 」を参照
- メタ評価 — Judge と人間の評価を突き合わせる際のサンプル元(次節で解説)
※ 副次的に、新メンバーのオンボーディングでも活用できます(「このプロダクトで何が OK / NG か」を具体例で共有できる)。
Human Annotation によるメタ評価#
Judge プロンプトを作ったら、すぐ本番投入……の前に、人間の評価と突き合わせるステップが必要です。このステップを挟むことで、Judge の判定に根拠を持たせることができます。Langfuse の Annotation Queues を使ったレビューフローについては「Langfuse で LLM 評価を効率化!活用方法徹底解説 」で解説しています。
手順:
- ゴールデンデータセットから 10〜20 件を抽出(データセット全体が大きい場合は代表的なケースを絞り込む)
- 同じ入出力を Human Annotation として人間 2 名(開発者 + ドメイン専門家)が独立して採点する(参考:2名が同じ Pass/Fail 判定になった件数の割合をアノテーター間一致率と呼びます。10 件中 8 件以上一致していれば評価基準が共有できている目安。8 件未満の場合は基準が曖昧なサインです)
- 人間同士で評価が割れた項目を以下の手順でレビューする
- 3a. 2 名ですり合わせを行い、合意できれば正解を確定する
- 3b. 合意できない場合は PdM や別のドメイン専門家を第三者として判断を仰ぐ
- 3c. 割れた判断とその結論は記録し、Judge プロンプトの採点基準に反映する
- 同じデータセットに対して Judge を実行し、スコアを記録する
- 評価軸ごとに Judge スコアと確定した人間スコアを比較し、乖離が多い評価軸があれば Judge プロンプトを修正
判断基準(本番投入の閾値):
直感的には「Judge と人間のスコアが一致した割合(Judge–人間 一致率)」を使いたくなります。ただし Pass/Fail のデータに偏りがあると、Judge–人間 一致率は見かけ上高くなります。たとえば 10 件中 9 件が Pass のサンプルで Judge が全件 Pass と返した場合、Judge–人間 一致率は 90% になりますが、Fail を全件見逃しています。
そこで有効なのが Cohen’s Kappa です。Cohen’s Kappa は「偶然の一致を取り除いた合意度」であり、単純な Judge–人間 一致率より偏りに頑健な指標です(ただし極端なクラス不均衡では Kappa 自体が低く出る性質もあるため、必ず Confusion Matrix と併読してください)。また Confusion Matrix(一致・不一致の内訳)を合わせて見ることで、Pass/Fail どちらを見逃しているかも把握できます。
目標値:Cohen’s Kappa 0.61 以上(Landis & Koch の解釈スケールで「Substantial=十分な一致」水準、あくまで目安)かつ Confusion Matrix の右上セル(Fail 見逃し)をゼロに近づける
- Cohen’s Kappa が 0.61 未満、または右上セルに件数がある場合は(どちらか一方でも)、ユースケースの重大性に応じて Judge プロンプトの見直しを検討する
確認方法: 本稿執筆時点(2026 年 4 月)では、Langfuse の Score Analytics(Beta)で人間スコアと Judge スコアを 2 つ並べると、以下の指標が自動表示されます。Beta 機能のため、今後の UI 変更や提供状況については Langfuse 公式ドキュメントを確認してください。
| 指標 | 意味 | 見方 |
|---|---|---|
| Agreement | 人間と Judge の一致率 | 参考値(クラスの偏りで歪む) |
| Cohen’s Kappa | 偶然の一致を除いた合意度(Landis & Koch スケール) | 0.61 以上(Substantial)を目標に |
| F1 Score | Precision と Recall の調和平均 | Fail 見逃しを重視するケース(不適切発言検知等)では Recall 寄りの F1 も参照 |
| Confusion Matrix | 一致・不一致の内訳(縦軸:人間の判定、横軸:Judge の判定) | 下表で読み方を確認 |
Confusion Matrix の見方(Langfuse の表示に合わせた順。Beta 機能のため軸ラベルは実際の画面で確認してください):
| Judge = False(Fail) | Judge = True(Pass) | |
|---|---|---|
| 人間 = False(Fail) | ✅ 正しく Fail と判定 | ❌ Fail の見逃し |
| 人間 = True(Pass) | ⚠️ Pass を過剰に Fail 判定 | ✅ 正しく Pass と判定 |
- 右上セル(人間=Fail・Judge=Pass)がゼロまたは少ない → Fail の見逃しが少ない
- 左下セル(人間=Pass・Judge=Fail)が多い → Pass を過剰に弾いている
LLM Judge は Pass を返しやすい傾向(Leniency Bias)があるため、右上セル(Fail 見逃し)には特に注意が必要です。ただしどちらを重視するかはユースケース次第で、不適切発言の検知など Fail の見落としが致命的なケースでは右上セルを重点的に確認し、それ以外では両セルをバランスよく見ます。
改善前(Judge プロンプト修正が必要な状態):
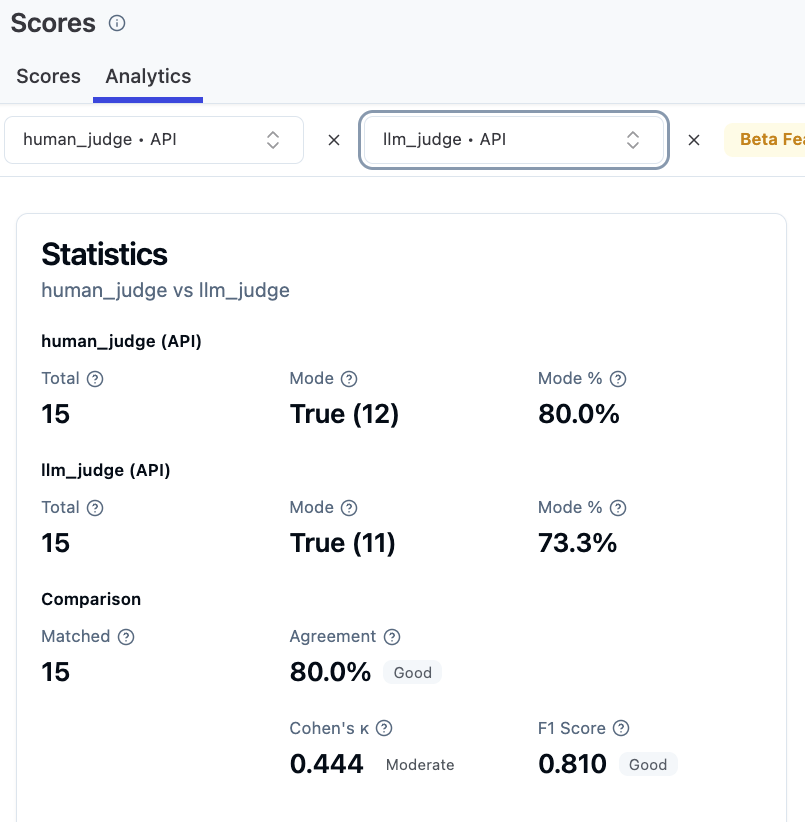
Agreement 80%、Cohen’s Kappa 0.444(Moderate)。Moderate は合意度が中程度で、目標の 0.61(Substantial)に届いていない。
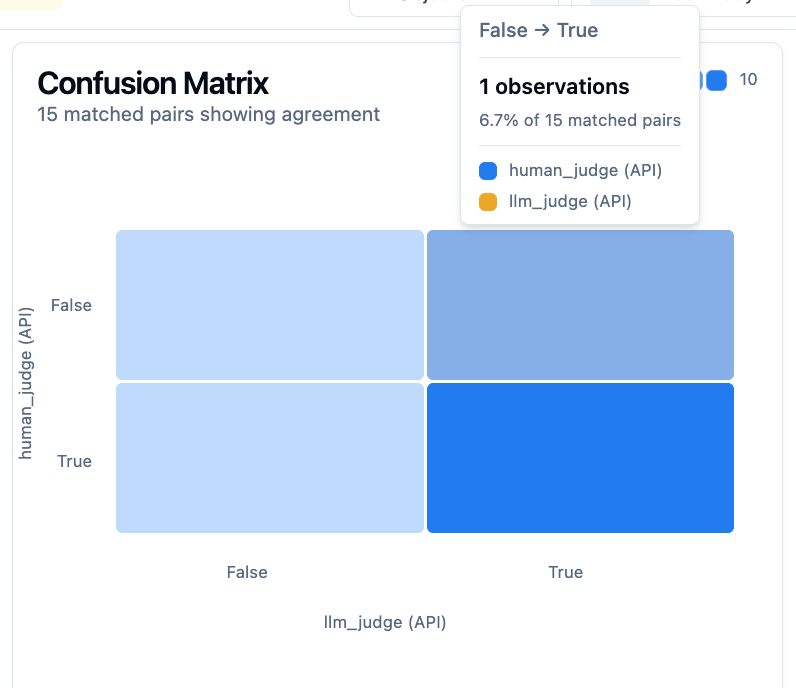
右上セル(人間=Fail・Judge=Pass)に 1 件の Fail 見逃しがある。
→ 目標未達のため Judge プロンプトの修正が必要。
改善後(本番投入 OK な状態):
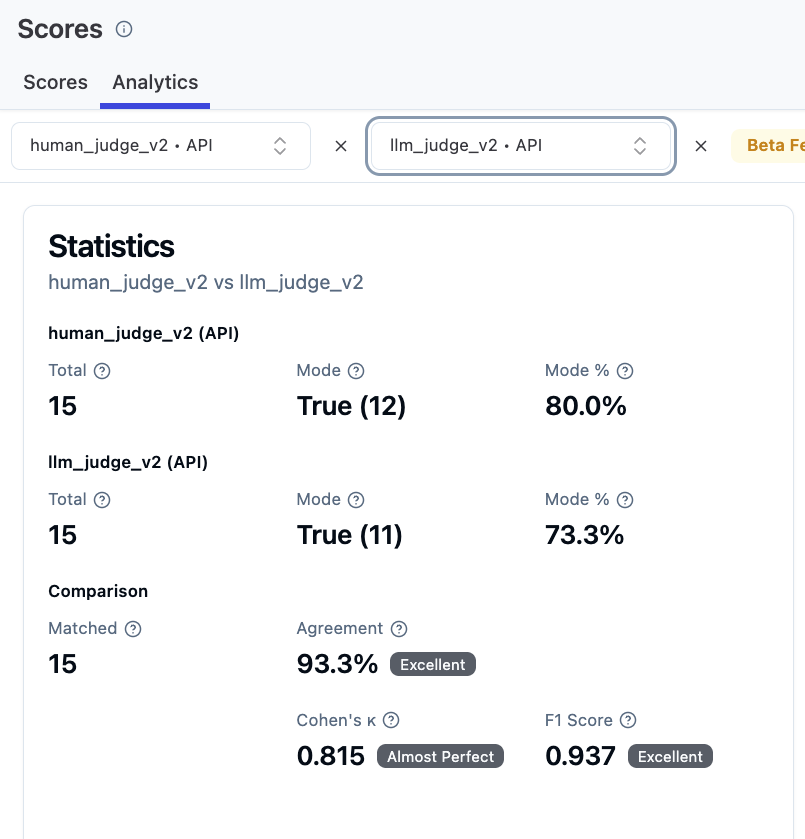
Agreement 93.3%、Cohen’s Kappa 0.815(Almost Perfect)。目標の 0.61(Substantial)を大きく上回る。
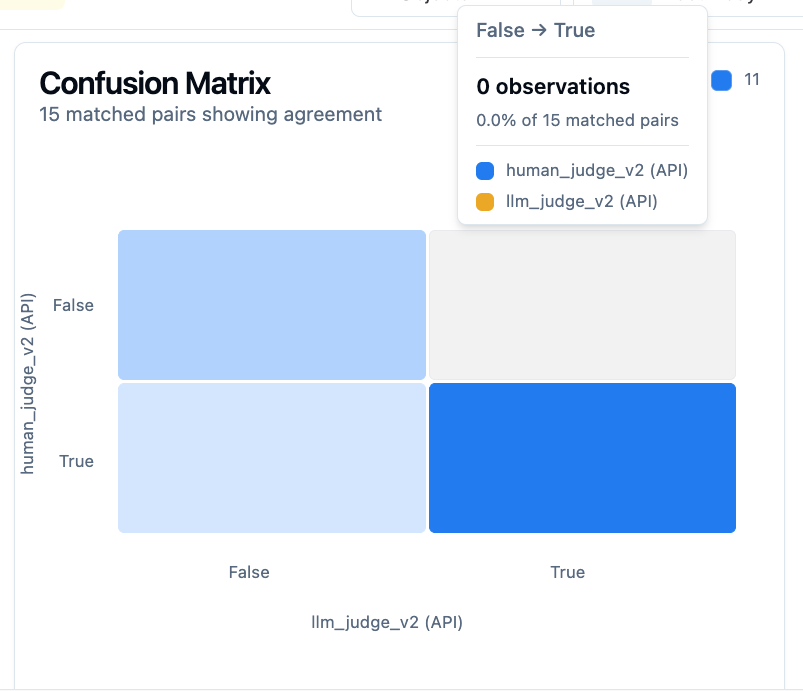
右上セル(Fail 見逃し)が 0 件。Fail の見逃しがなくなった。
→ 本番投入 OK な状態。
判定が食い違ったトレースを見る際は、以下に着目すると Judge プロンプトの改善ポイントが見つかりやすいです:
- 日本語の婉曲表現・敬語の差分で Judge が誤評価していないか
- 「たぶん〜だと思います」のような推測表現を Judge が見逃していないか
何度プロンプトを修正しても Kappa が改善しない場合は、以下を検討してください:
- Judge モデルを上位モデルに変える — Haiku → Sonnet など、モデル性能不足が原因のケース
- 評価軸を分割する — 1つの軸が複数の概念を含んでいる可能性(例:「有用性」を「正確性」と「網羅性」に分割)
- ゴールデンデータセットに境界事例を追加する — Judge が迷いやすいグレーゾーンの典型例を補充する
初回のメタ評価の工数目安は 2〜3 時間(評価軸 1〜2、サンプル 10〜20 件、2 名で採点する場合)です。初回を通しておくと、機能追加・モデル変更時のメタ評価のベースラインになります。
なお、評価を繰り返す中で専門家の判断基準自体が徐々に変化していく「Criteria Drift(評価基準の変容)」という現象も報告されています(詳細は AI品質マネジメントイニシアティブ WG2 2025年度 課題対策事例集 を参照)。最初から完璧な基準は作れず、評価を通じてあるべき基準に気がついていくものです。定期的なメタ評価が必要な理由の一つでもあります。
まとめ#
本記事では、評価基盤の「設計フェーズ」として以下を解説しました。
| フェーズ | やること |
|---|---|
| 出発点 | プロンプトのルール分解 + トレース 50 件の目視確認 |
| 評価の仕組みづくり | 評価方法選定・Judge プロンプト作成 → ゴールデンデータセット構築 → メタ評価 |
Judge の精度が確認できたら、次は「誰が・いつ・どうやって」評価を運用するかの設計に進みます。
→ 続きは「LLMOps:評価基盤の運用編 — Langfuse 活用 」をご覧ください(運用設計・改善サイクル・コスト管理を解説します)。
参考#
- Automated Evaluations - Langfuse Blog
- AI品質マネジメントイニシアティブ WG2 2025年度 課題対策事例集 - AI品質マネジメントイニシアティブ WG2
- LLMOpsとは? MLOpsとの違いや生成AIの評価について解説 - ガオ株式会社ブログ
- Langfuse で LLM 評価を効率化!活用方法徹底解説 - ガオ株式会社ブログ
- Langfuse の Observation レベル評価:「どのステップが悪いのか」をスコアで特定できるようになった - ガオ株式会社ブログ
- LangfuseのExperiments Compare ViewのBaseline機能を解説 - ガオ株式会社ブログ
- Langfuseデータセット構築ガイド:UI・CSV・SDKの徹底比較 - ガオ株式会社ブログ
- Langfuseにおける個人情報(PII)のマスキング - ガオ株式会社ブログ
Langfuse 公式ドキュメント#
- Score Analytics - Langfuse Docs
- LLM-as-a-Judge - Langfuse Docs
- Annotation Queues - Langfuse Docs
- Experiments - Langfuse Docs