LMアプリケーションの可観測性(オブザーバビリティ)を確保しようとする際、Langfuse SDK や OpenTelemetry SDK をアプリケーション側に組み込んで計装するのが一般的なアプローチですが、これは多少なりとも手間がかかることと、社内のエージェントを勝手に動かす人などが意図的に観測されないように対応しないこともありえるでしょう。
しかしながら、LLM への呼び出しを LLM Gateway に集約することで、アプリケーション側での計装が不要になり、ガバナンスを高めることにも寄与します。
そこでこの記事では、Pythonアプリ(Google ADKエージェント / google-genai SDK)からのLLM呼び出しを API gateway である Kong経由に切り替え、Kongの組み込みOpenTelemetr プラグインから Langfuse の OTLP/HTTP エンドポイントへ直接トレースを送信するまでの手順をまとめます。
本記事の作成にあたりまして、Langfuse Night #3 の川村さんの登壇内容を参考にさせていただきました。ありがとうございます! https://www.docswell.com/s/shukawam/Z2QJD9-langfuse-and-kong-gateway
検証環境#
| コンポーネント | バージョン | 備考 |
|---|---|---|
| Kong Gateway | 3.10 | OSS版を利用 |
| Kong plugins | bundled | ai-proxy, opentelemetry を使用 |
| google-adk | 1.x | |
| google-genai SDK | 1.x | |
| Langfuse | Cloud | OTLP/HTTP endpoint を使用 |
この記事での検証はネットワーク的にはローカルでの docker compose を前提としています。Kongとアプリは同一Dockerネットワーク内で通信し、Kong自体は外部公開しません。
全体構成#
アーキテクチャの全体像は以下の通りです。
User (curl)
↓
MCP Server / ADK Agent (Python)
↓ genai SDK (base_url → Kong)
Kong AI Gateway(Docker network 内部)
├── ai-proxy plugin → LLM リクエストを Vertex AI に送信
└── opentelemetry plugin → Langfuse OTLP/HTTP endpointどのプラグインで Langfuse に送るか#
Langfuse の Kong 連携ガイド では、kong-plugin-ai-tracing を導入してトレースする手順が「Recommended」として案内されています。
一方で今回は、追加プラグインの導入・管理を増やしたくなかったので、Kong 組み込みの opentelemetry プラグインを使いました。Kong 側は OTLP/HTTP(Protobuf)で送信でき、バックエンド直送も Collector 経由も選べます。
実装手順#
細かい実装の手順やConfigはざっくりこちらにまとめました。ご参考までにどうぞ。
1. Kong 設定#
kong.yaml
_format_version: "3.0"
services:
- name: gemini-service
# Service 定義上 url は必須だがダミー値。
# ai-proxy が upstream を置き換え、Vertex AI へ直接接続するため転送されない。
url: http://httpbin.konghq.com
routes:
- name: gemini-route
paths:
- /gemini
plugins:
- name: ai-proxy
config:
route_type: llm/v1/chat
llm_format: gemini
logging:
log_statistics: true
auth:
gcp_use_service_account: true
gcp_service_account_json: '${GCP_SERVICE_ACCOUNT_JSON}'
# 本番環境では、サービスアカウント鍵(JSON)の配布・保管・ローテーションが
# セキュリティ上の課題・運用負荷になりやすいため、サービスアカウントキーを
# 使わない認証を推奨します。今回はあくまで検証用ということでご理解ください。
model:
provider: gemini
name: gemini-2.5-flash
options:
gemini:
api_endpoint: us-central1-aiplatform.googleapis.com
project_id: ${GCP_PROJECT_ID}
location_id: ${GCP_LOCATION_ID}
- name: opentelemetry
config:
traces_endpoint: ${LANGFUSE_HOST}/api/public/otel/v1/traces
headers:
Authorization: "Basic ${LANGFUSE_AUTH_BASE64}"2. コード側でKongに向ける#
コード記載例
KONG_BASE_URL = os.getenv("KONG_BASE_URL", "http://kong:8000/gemini")
model = Gemini(model="gemini-2.5-flash", base_url=KONG_BASE_URL)
client = genai.Client(http_options={"base_url": KONG_BASE_URL})3. docker compose(最小構成)#
docker-compose.yaml
services:
kong:
build:
context: .
dockerfile: Dockerfile.kong
environment:
KONG_DATABASE: "off"
KONG_DECLARATIVE_CONFIG: /opt/kong/kong.yml
KONG_PLUGINS: bundled
KONG_PROXY_LISTEN: "0.0.0.0:8000"
# 詰まりどころ(後述)
KONG_NGINX_PROXY_CLIENT_BODY_BUFFER_SIZE: "8m"
LANGFUSE_PUBLIC_KEY: ${LANGFUSE_PUBLIC_KEY}
LANGFUSE_SECRET_KEY: ${LANGFUSE_SECRET_KEY}
LANGFUSE_HOST: ${LANGFUSE_HOST:-https://cloud.langfuse.com}
GCP_PROJECT_ID: ${GCP_PROJECT_ID}
GCP_LOCATION_ID: ${GCP_LOCATION_ID}
volumes:
- ./credentials/service-account-key.json:/app/credentials/service-account-key.json:ro
app:
environment:
- KONG_BASE_URL=http://kong:8000/gemini
- GOOGLE_API_KEY=dummy
depends_on:
- kong動作確認#
1. Kong の起動確認#
docker compose exec kong kong health2. Kong 経由で Gemini が応答するか#
docker compose exec kong curl -s -X POST http://localhost:8000/gemini/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"messages":[{"role":"user","content":"hello"}],"model":"gemini-2.5-flash"}' \ | jq .choices[0].message.content3. Langfuse にトレースが届くか#
Langfuse の Traces を開いて確認します。
実行結果 (Traceの比較)#
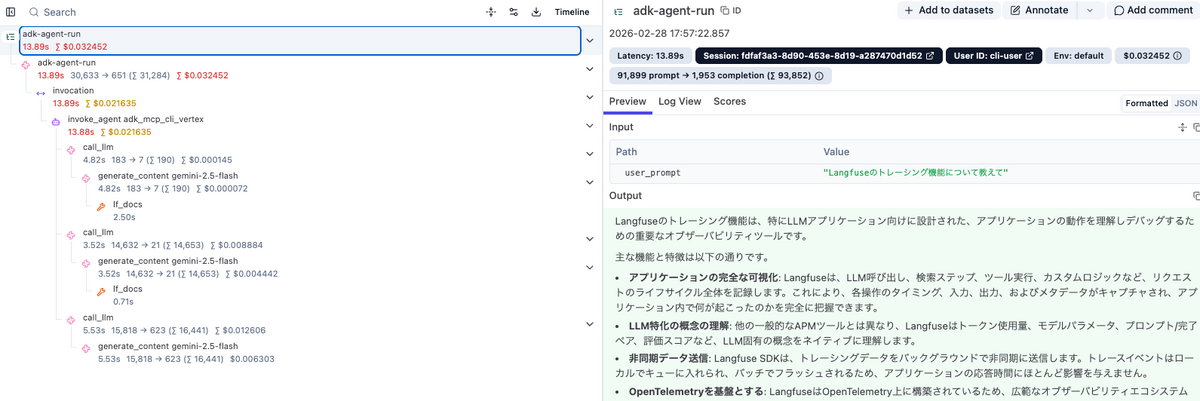
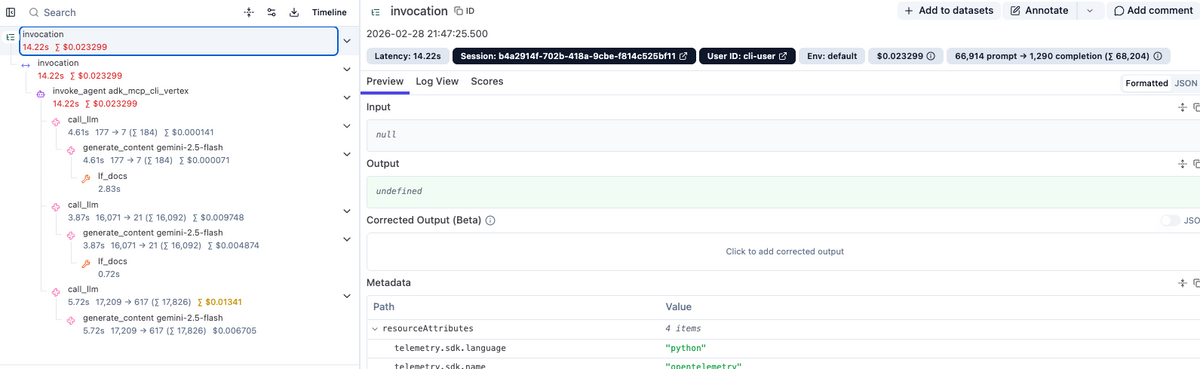
実装できたら、Langfuseの画面で結果を確認してみます。
すると、エージェント側で計装したもの(パターンA) と Kong経由で自動でLangfuseにTraceを飛ばすもの (パターンB) では微妙に確認できるものが異なることに気がつくと思います。
両者とも基本的な要素は全てカバーされており、構造・トークン・モデル名・レイテンシーなどを確認することができますが、パターンB においては、Traceレベルの Input/Outputに情報が入らず、Promptとの紐付けなどもできません。一方でパターンAはエージェント側で計装しますので、もちろんどのようにでも表示可能です。
パターンA. Kong を通さないもの (エージェント側で計装)
おまけ: 実装時の注意メモ#
1. リクエストボディが大きいと ai-proxy が 400 を返す#
エージェントがツールを使うと、2回目以降の LLM 呼び出しで会話履歴+ツール結果が乗り、ボディが急に大きくなります。Nginx 側のデフォルトが小さいと、ボディがテンポラリに逃げたりして ai-proxy の処理が崩れ、次のエラーに当たりました。
- 400 “request body doesn’t contain valid prompts”
- ツール不使用だと通るが、ツール使用だと落ちる(この分岐が地味に厄介)
対策:先ほどの compose ファイルにもあった通り、Nginx のバッファサイズを上げます。
KONG_NGINX_PROXY_CLIENT_BODY_BUFFER_SIZE: "8m"2. preserve 前提で組むと 3.11 以降で詰まる#
preserve は 3.11.0.0 で deprecated です。将来削除される前提なので、早めに “新しい route_type”(今回なら llm/v1/chat)に寄せておくのが安全かと思われます。
まとめ:#
今回は、Kong AI GatewayとLangfuseを用いて、アプリケーション側に計装SDKを組み込まずにLLMのオブザーバビリティを確保する手順をご紹介しました。
ゲートウェイ層にLLMの呼び出しとトレース送信の責務を集約することで、アプリケーション側のコードを汚さずに素早く観測を始められるのは、この構成の大きな強みです。