はじめに#
LLMアプリケーション開発において、テキストだけでなく画像や音声などのマルチモーダルなデータを扱うケースが増えています。Langfuseは2024年8月に初めてマルチモーダルトレースのサポートを発表し、同年11月には画像、音声、PDFなどの添付ファイルにも対応する完全なマルチモーダルサポートを実現しました。
当該機能は長らくpreviewとされていましたが、先日GAとなったようです(※中の人がSlackでそう言ってました)。
そこで本記事では、Langfuseのマルチモーダル機能の概要、具体的な使い方、そして利用時の注意点について解説します。
Langfuseマルチモーダル機能の概要#
たとえば画像ファイルを含んだトレースを送信した場合、LangfuseのWebUI上では以下のように表示されます。
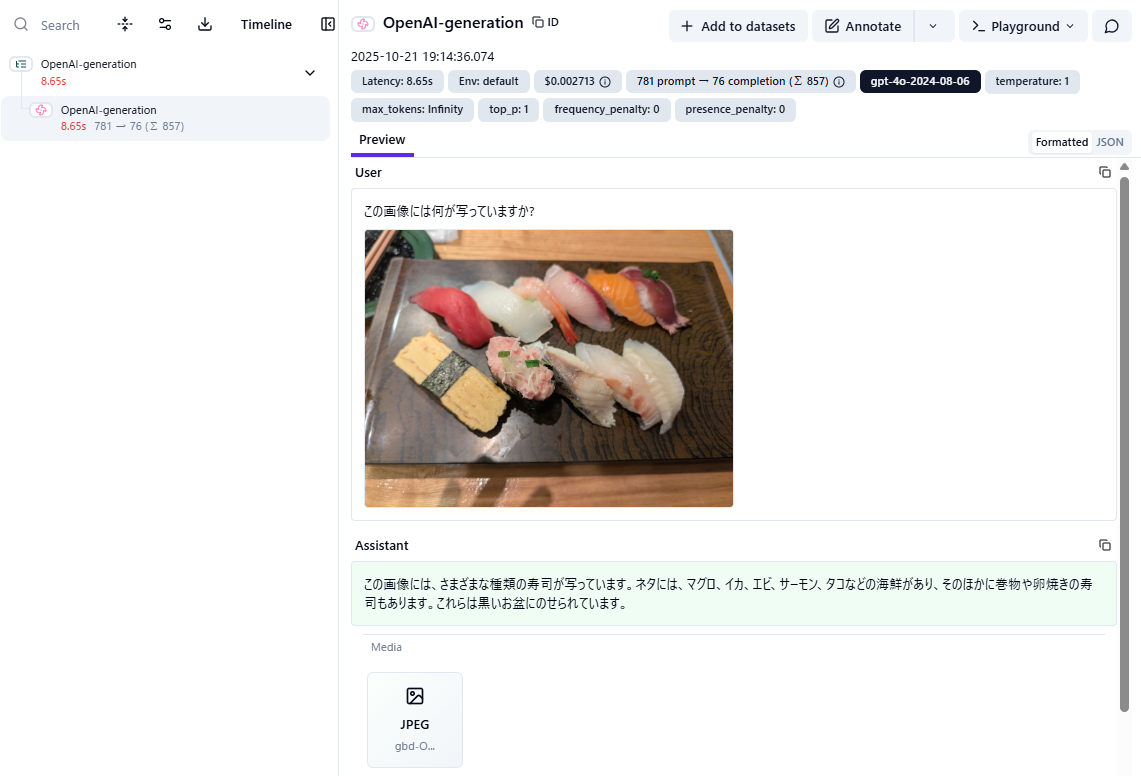
このように、LLMを呼び出す際に画像データが含まれていた場合、テキストデータだけでなく画像データも同時に確認でき、改善活動の効率が大いに向上します。
(※余談ですが、gpt-4oは寿司ネタにそこまで詳しくないのかもしれません。上記画像にタコにみえるネタはないようにみえるので…)
また、音声ファイルが添付されたトレースは以下のように表示されます。
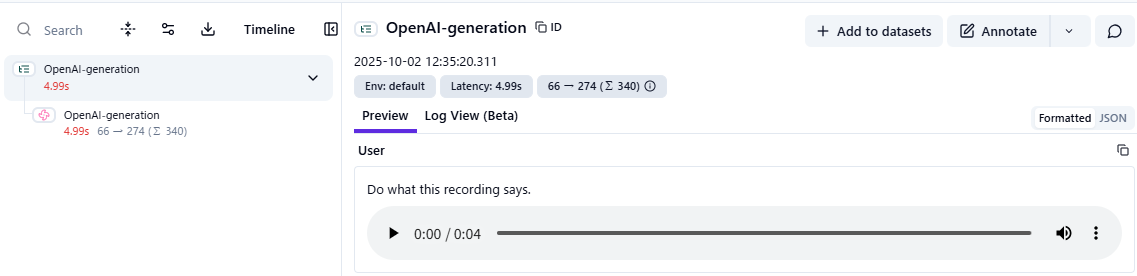
UI上に表示される再生ボタンを押すことで音声が再生できます。こちらも画像ほどではないにせよ、WebUIから直接LLMに送信した音声データの内容が確認できるため、LLMアプリケーションの挙動確認を効率よく行えるようになります。
対応しているファイル形式#
Langfuseは以下のメディアファイル形式に対応しています:
- 画像: PNG、JPG、WEBP
- 音声ファイル: MPEG、MP3、WAV
- その他の添付ファイル: PDF、プレーンテキスト
これらのファイルは、トレースやObservationのinput、output、metadataフィールドに含めることができます。
主な特徴#
- 自動処理: Base64エンコードされたデータURIは、Langfuse SDKが自動的に検出し処理されます
- 外部URL対応: 外部URLで参照されるメディアファイルもUI上でインライン表示可能です
- 効率的な保存: メディアファイルはトレースデータと分離され、オブジェクトストレージに直接アップロードされます
- 重複排除: 同じファイルは自動的に重複排除され、参照IDのみが保存されます
アーキテクチャ#
Langfuseは、パフォーマンスと効率性を最適化するために以下のような仕組みを採用しています:
- メディアファイルはクライアント側でトレースデータから分離
- AWS S3または互換性のあるオブジェクトストレージに直接アップロード
- トレース内にはmediaIdへの参照のみを保持
- UI側でmediaIdを検出し、メディアファイルをインライン表示
使い方#
1. Base64エンコードされたメディアの自動処理(最も簡単)#
最新バージョンのLangfuse SDKであれば、通常のトレース送信設定を実施しておくだけで、Base64エンコードされたメディアファイルが自動的にLangfuseにアップロードされます。
OpenAI SDKとの連携例(画像の場合):
from langfuse.openai import openai
# Langfuse統合が有効化されたOpenAIクライアント
client = openai.OpenAI()
# 画像を含むリクエスト(Base64エンコードされた画像も自動処理)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像には何が写っていますか?"},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,/9j/4AAQSkZJRg..."
}
}
]
}
]
)SDK側で自動的に画像を抽出し、Langfuseのオブジェクトストレージにアップロード後、トレースに参照を記録します。
また、音声データの場合でもBase64エンコードして利用するぶんには同様に自動的に検出&アップロードされます。
#
2. 外部URLによる参照#
外部URLで画像を参照する場合も、Langfuse UIで自動的にインライン表示されます:
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像を分析してください"},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
}
]
}
]
)この場合、メディアファイルはLangfuseのストレージにアップロードされず、元のURLからLangfuse WebUI上に直接表示されます。
3. LangfuseMediaクラスを使ったカスタム制御#
より細かい制御が必要な場合や、Base64エンコードされていないメディアを扱う場合は、LangfuseMediaクラスを使用します:
from langfuse import get_client, observe
from langfuse.media import LangfuseMedia
@observe()
def process_document():
langfuse = get_client()
# PDFファイルを読み込む
with open("document.pdf", "rb") as pdf_file:
pdf_bytes = pdf_file.read()
# LangfuseMediaでラップ
pdf_media = LangfuseMedia(
content_bytes=pdf_bytes,
content_type="application/pdf"
)
# トレースのメタデータに追加
langfuse.update_current_trace(
metadata={"document": pdf_media}
)
# または、入力や出力に含める
langfuse.update_current_span(
input={"document": pdf_media}
)#
セットアップと料金#
Langfuse Cloudを使用する場合#
Langfuse Cloudでは、マルチモーダル添付ファイルは現在無料で利用できます。ただし、将来的には大規模なマルチモーダルトレースに伴うストレージとコンピューティングコストを考慮した課金体系が導入される可能性があることに留意してください。
セルフホスティングの場合#
セルフホスティング環境では、独自のオブジェクトストレージバケットを設定する必要があります:
- AWS S3または互換ストレージ(Google Cloud Storage、Azure Blob Storage、Minio等)を用意
- 環境変数LANGFUSE_S3_MEDIA_UPLOAD_*を設定
- ストレージバケットは、SDK経由の直接アップロードとブラウザからのメディアアセット取得をサポートするため、公開解決可能なホスト名を持つ必要があります
設定の詳細はセルフホスティングドキュメント を参照してください。
注意事項と制約#
1. 現在サポートされていない機能#
- Playgroundでの使用: マルチモーダルコンテンツはまだPlaygroundでサポートされていません
- Dataset Items: データセットアイテムでのマルチモーダルコンテンツもまだサポート対象外です
2. セキュリティと検証#
- メディアアップロードには署名付きURL(presigned URL)が使用されます
- コンテンツ長、コンテンツタイプ、SHA256ハッシュによる検証が行われます
- ファイルの一意性は、プロジェクト、コンテンツタイプ、SHA256ハッシュによって判定されます
3. ストレージ容量の管理#
マルチモーダルデータは通常のトレースデータよりも大きなストレージを消費します。特にセルフホスティングの場合は、ストレージ容量とコストの管理に注意してください。
4. トラブルシューティング#
画像が正しく表示されない場合:
- セルフホスト環境で画像がインラインではなくボタンとして表示される場合、LANGFUSE_S3_MEDIA_UPLOAD_FORCE_PATH_STYLE=trueの設定が必要な場合があります
- ストレージバケットの公開設定と署名付きURLの有効期限を確認してください
- Langfuseのバージョンがマルチモーダルサポートに対応しているか確認してください(v2.93.2以降推奨)
まとめ#
Langfuseのマルチモーダル対応により、テキストだけでなく画像、音声、文書ファイルなどを含むLLMアプリケーションの動作を包括的に観察できるようになりました。
主なメリット:
- Base64エンコードされたメディアの自動処理により、開発者の手間を削減
- 外部URLとカスタムアップロードの両方に対応し、柔軟な実装が可能
- 効率的な重複排除とストレージ管理
- 既存のOpenAI SDK、LangChain、LlamaIndexなどとのシームレスな統合
マルチモーダルAIアプリケーションの開発・運用において、Langfuseは強力な観察性とデバッグ機能を提供します。まずは最新バージョンのSDKにアップグレードして、自動処理の恩恵を受けることから始めてみてください。