はじめに#
LiveKit Agentsは、音声AIアプリケーションを構築するためのオープンソースフレームワークです。本記事では、Langfuseを使った観測可能性の実装と、その際に遭遇したトレース分離問題の解決方法を紹介します。
想定読者
- OpenTelemetry、Langfuseの基礎知識がある方。
- LiveKit Agentsで音声AIアプリケーションを構築している方。
LiveKitとは#
LiveKitは、リアルタイム音声・映像通信のためのオープンソースプラットフォームです。WebRTCをベースにしており、音声AIエージェントをはじめとする様々なリアルタイムアプリケーションの構築に利用できます。
LiveKitの主な特徴#
Room中心の設計#
LiveKitでは、Roomという仮想空間を中心とした設計になっています。
- Room: 参加者が集まる仮想空間。会議室やチャットルームのようなイメージ。
- Participant: Roomに参加するユーザーやエージェント。
- Agent: プログラマブルなAI参加者。人間のようにRoomに参加し、音声で会話できる。
WebRTCによる低レイテンシ通信#
従来のHTTP/WebSocketと比較して、WebRTCは音声・映像のリアルタイム通信に最適化されており、低レイテンシで高品質な通信が可能です。
多様なクライアントSDK#
ブラウザ、iOS、Android、Unityなど、主要なプラットフォームに対応したSDKが提供されており、幅広い環境で利用できます。
詳細は公式ドキュメント をご覧ください。
LiveKit Agentsを使うメリット#
1. 統一されたインターフェース#
STT、LLM、TTSの各プロバイダーを統一されたAPIで扱えるため、プロバイダーの切り替えが容易です。
2. 本番環境に対応した機能#
VAD(Voice Activity Detection)、Turn Detection、エラーハンドリングなど、実用的な機能が標準で提供されています。
3. リアルタイム性の高さ#
WebRTCベースの設計により、エンドツーエンドで低レイテンシな音声通信が実現できます。
4. 柔軟なアーキテクチャ#
STT+LLM+TTSの従来型パイプラインと、OpenAI Realtime APIなどのSpeech-to-Speechモデルの両方に対応しています。
料金プラン#
LiveKit CloudのFree Planでは、月間1,000分のAgent Sessionが無料で利用できます。これにより、開発段階やプロトタイプ作成において、コストを気にせず気軽に始められます。
詳細は料金ページ をご確認ください。
環境構築#
今回は、LiveKit Agentsの公式リポジトリにあるサンプルコード(langfuse_trace.py) を使用します。このサンプルには、Langfuse統合の基本実装と、2つの異なるタイプのエージェント(STT+LLM+TTS構成とRealtime API構成)が含まれています。
セットアップの流れは以下の通りです。
- LiveKit CloudでAPI Keyを取得。
- 必要な環境変数を設定。
- サンプルコードをクローンして依存関係をインストール。
- 初回セットアップコマンドを実行。
それでは、具体的な手順を見ていきましょう。
LiveKitアカウント作成とAPI Key取得#
まず、https://cloud.livekit.io/login にアクセスしてアカウントを作成します。アカウント作成後、Settings → API keys → Create key の順にクリックし、生成されたAPI KeyとSecretをコピーして保存します。
必要な環境変数の設定#
プロジェクトルートに.envファイルを作成し、以下の環境変数を設定します。
# Langfuse
LANGFUSE_SECRET_KEY=sk-lf-**
LANGFUSE_PUBLIC_KEY=pk-lf-**
LANGFUSE_HOST=https://**
# LiveKit
LIVEKIT_URL=wss://**.livekit.cloud
LIVEKIT_API_KEY=**
LIVEKIT_API_SECRET=**
# OpenAI
OPENAI_API_KEY=sk-proj-**サンプルコードのセットアップ#
以下のコマンドでサンプルコードを取得し、環境をセットアップします。まず、リポジトリをクローンして該当ディレクトリに移動します。
git clone https://github.com/livekit/agents.git
cd agents/examples/voice_agents次に、仮想環境を作成してアクティベートします。
python -m venv venv
source venv/bin/activate依存関係をインストールし、初回のみ必要なファイルをダウンロードします。
pip install -r requirements.txt
python langfuse_trace.py download-files使用バージョン
- Python 3.12.12
- livekit-agents 1.3.2
- livekit-plugins-openai 1.3.2
- livekit-plugins-deepgram 1.3.2
- livekit-plugins-silero 1.3.2
サンプルコードの実行#
以下のコマンドでコンソールモードでエージェントを起動します。
python langfuse_trace.py consoleこのサンプルコードには、以下の機能が実装されています。
実装されているエージェント#
- Kelly: Deepgram(STT)、GPT-4o-mini(LLM)、OpenAI TTS(TTS)を組み合わせた従来型パイプライン。
- Alloy: OpenAI Realtime APIを使用したSpeech-to-Speechエージェント。
ツール#
- lookup_weather: 天気情報を取得するツール(仮想データを返す)。
エージェント交代機能#
KellyとAlloyは相互に交代可能です。Kellyに"transfer to Alloy"と話しかけるとAlloyに交代し、逆にAlloyに"transfer to Kelly"と話しかけるとKellyに戻ります。
LiveKitを使ってみた感想#
実際にLiveKit Agentsを使用して音声AIアプリケーションを構築してみた感想をいくつか紹介します。
CLIが見やすく使いやすい#
LiveKitのCLIは非常に見やすく設計されており、ログの確認やデバッグが容易でした。音声認識の結果やエージェントの応答がリアルタイムで表示されるため、開発体験が良好です。
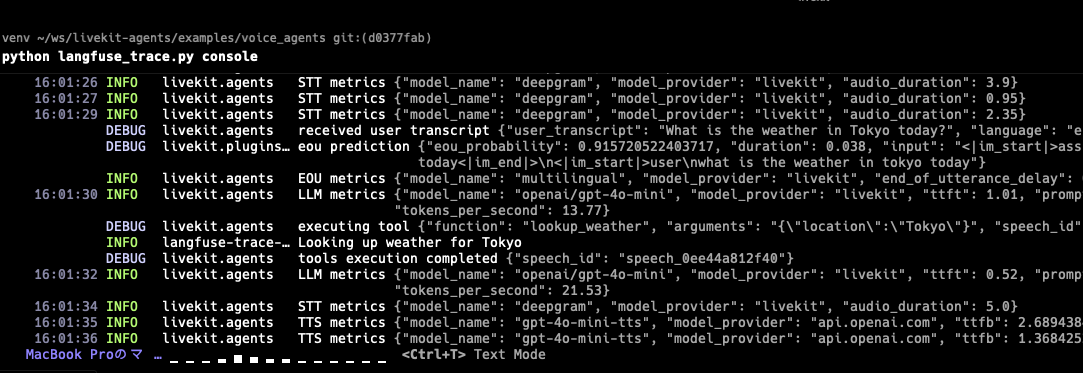
複数エージェントとの会話が簡単に実装できる#
今回のサンプルでは、KellyとAlloyという2つのエージェントを切り替えながら会話できました。エージェントの切り替えロジックがシンプルに実装されており、複雑な状態管理が不要な点が印象的でした。
STT+LLM+TTSのエージェントでも非常に速い#
当初、Realtime APIと比較してSTT+LLM+TTSパイプラインはレイテンシが高いのではないかと懸念していました。しかし、実際に使用してみると、体感的な遅延はほとんど感じられず、自然な会話が可能でした。
STT+LLM+TTSでも高速な理由#
LiveKit AgentsのSTT+LLM+TTSパイプラインが高速な理由は、以下のような最適化技術が組み込まれているためです。
1. プリエンプティブ生成(Preemptive Generation)#
preemptive_generation=True,ユーザーの発話が完全に終わる前に、部分的な転写結果に基づいて応答生成を開始します。これにより、ユーザーが話し終わった瞬間にエージェントが応答できます。
2. ストリーミングTTS#
tts=tts.StreamAdapter(
tts=openai.TTS(),
text_pacing=True,
),LLMがテキストを生成し次第、TTSが音声を順次送信します。全文生成を待たずに最初の音声が届くため、体感レイテンシが大幅に短縮されます。
3. WebRTCによる低レイテンシ通信#
HTTP/WebSocketよりも低レイテンシなWebRTCプロトコルを使用しているため、ネットワーク遅延が最小限に抑えられます。
4. 非同期並列処理#
STT、LLM、TTSが非同期で並列実行されるため、各処理の完了を待たずに次のステップに進めます。
5. 最適化されたパイプライン#
- VAD(Voice Activity Detection): 発話の開始/終了を正確に検出。
- Turn Detection: 会話のターンを適切に判断。
- インスタント接続: マイク入力をバッファリングして即座に処理開始。
実測値#
Langfuseのタイムライン表示で確認したところ、ユーザーが話し終わってからエージェントが話し始めるまでの時間は以下の通りでした。
- STT+LLM+TTS: 約2.33秒
- Realtime Model: 約0.65秒
数値で見ると差がありますが、体感的には両者とも自然な会話ができるレベルでした。STT+LLM+TTSでも十分に実用的な速度が出ていることが確認できました。
トレースがバラバラになる問題を発見#
期待していた構造#
Langfuseの公式統合ガイド では、以下のような階層化された単一のトレース構造が示されています。
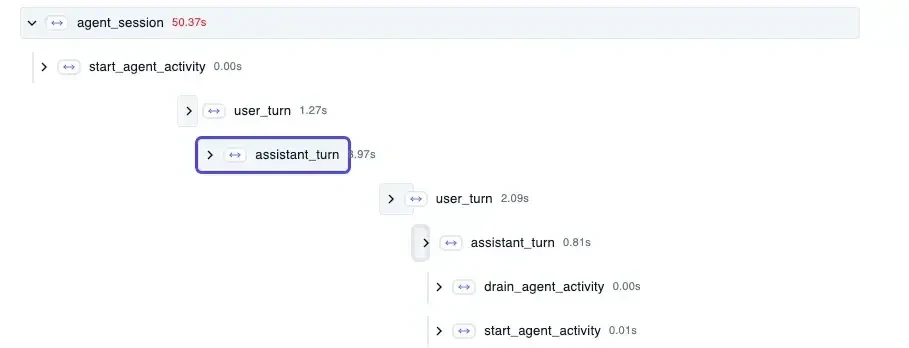
実際の構造#
しかし、実際にサンプルコードを実行してみると、各アクティビティが独立したトレースとして記録されてしまいました。
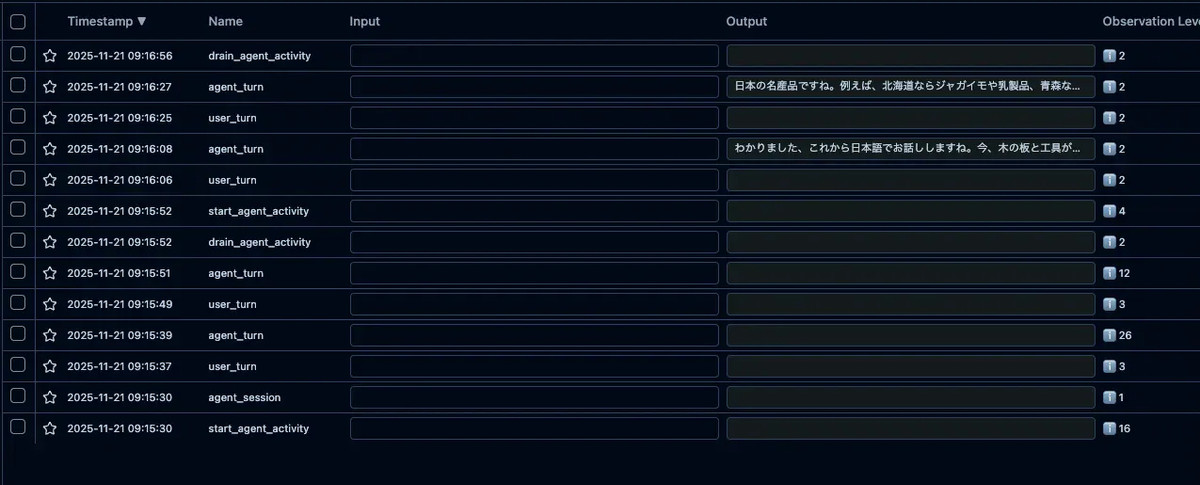
- agent_session
- start_agent_activity(エージェント入室)
- user_turn
- agent_turn
- drain_agent_activity(エージェント退室)
画像中の9:15:52付近を見ると、drain_agent_activityとstart_agent_activityが連続しています。これは、Kelly(STT+LLM+TTS)からAlloy(Realtime Model)へのエージェント交代を示しています。
この問題はGitHub Discussion でも報告されています。
user_turnとagent_turnの詳細#
トレースの詳細を見てみると、どちらのモデルでもuser_turnとagent_turnという基本構造は共通していました。しかし、内部の詳細度が大きく異なるようです。
user_turn(共通)#
どちらのモデルでも、ユーザーの発話に関する情報が記録されます。転写テキスト、信頼度スコア、発話時間などが含まれます。
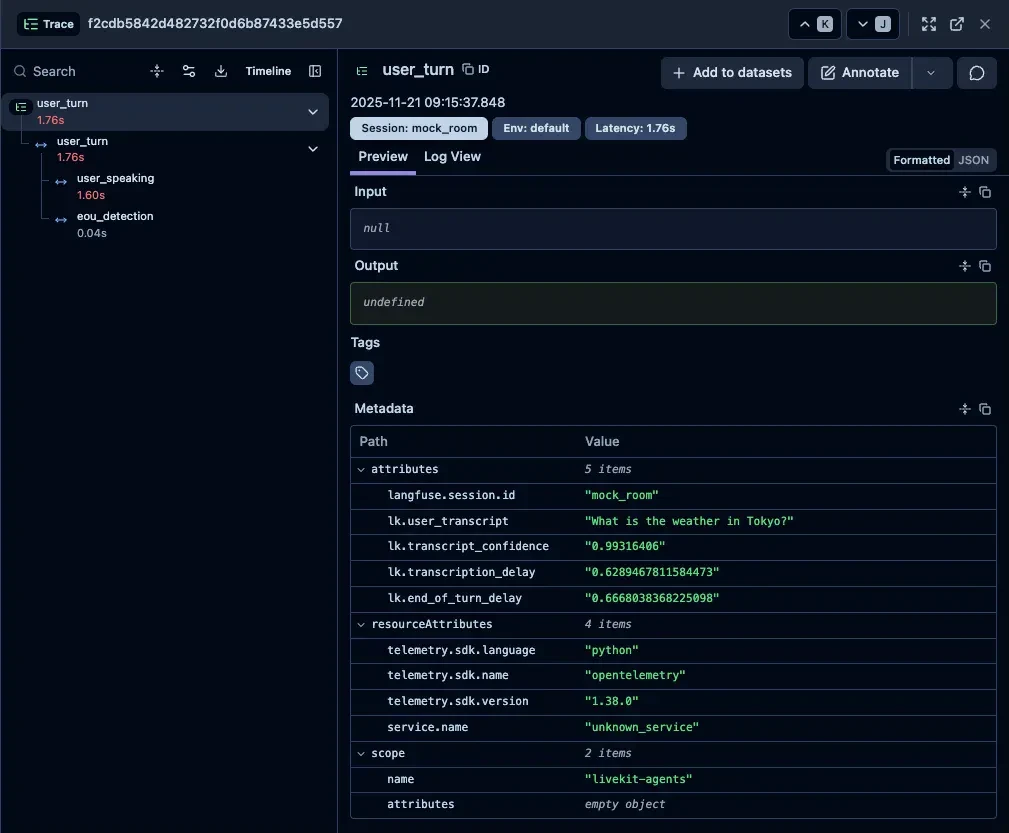
agent_turn(STT+LLM+TTS)#
パイプラインの各ステップが詳細に記録されます。
- llm_node: LLMへのリクエスト。
- llm_request: 実際のAPI呼び出し。
- tts_node: TTSへのリクエスト。
- tts_request: 実際の音声合成。
- function_tool: ツール呼び出し(ツール使用時のみ)。
このように各ステップが可視化されるため、ボトルネックの特定や最適化がしやすくなります。
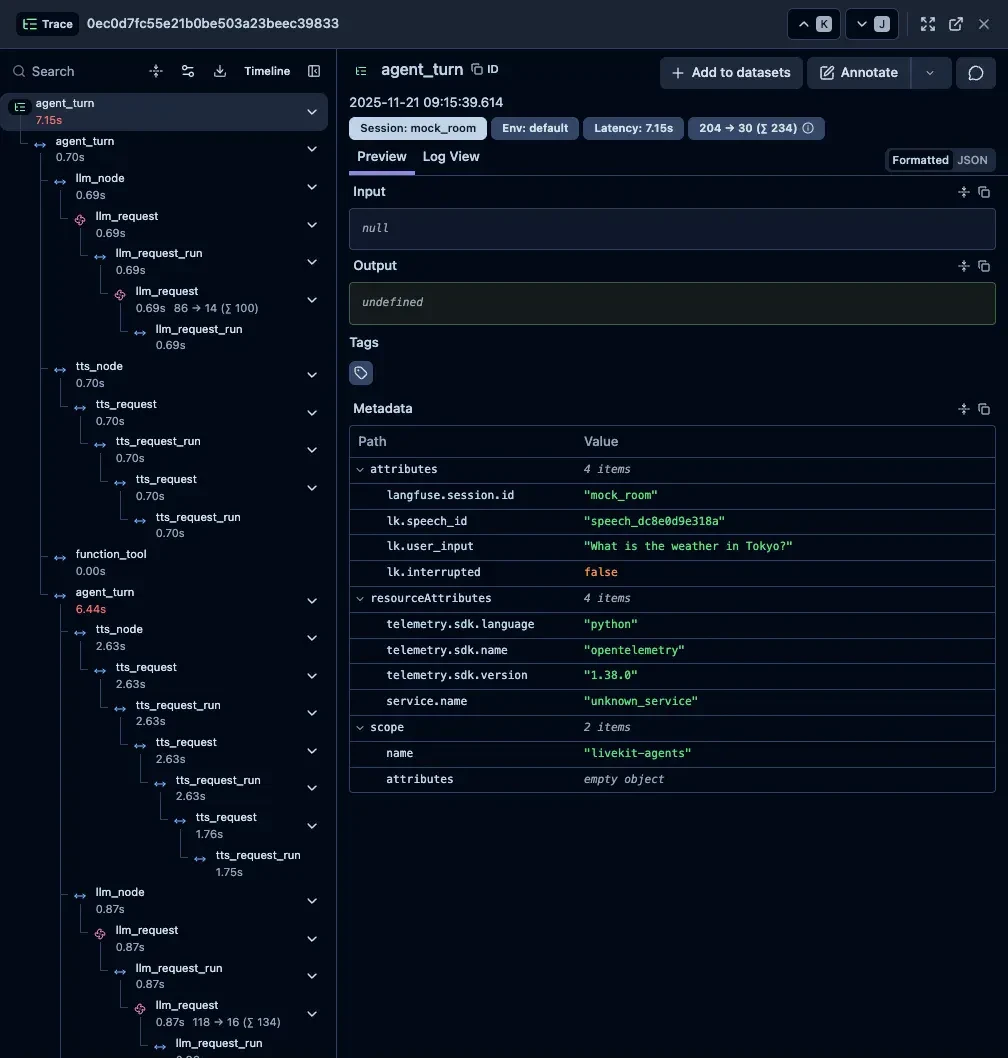
agent_turn(Realtime Model)#
使用しているOpenAI Realtime APIはSpeech-to-Speechモデルのため、内部処理が抽象化されています。STT、LLM、TTSといった明示的な分離がなく、シンプルな構造になっています。
また、Realtime ModelだけOutputがトレースに表示されました。
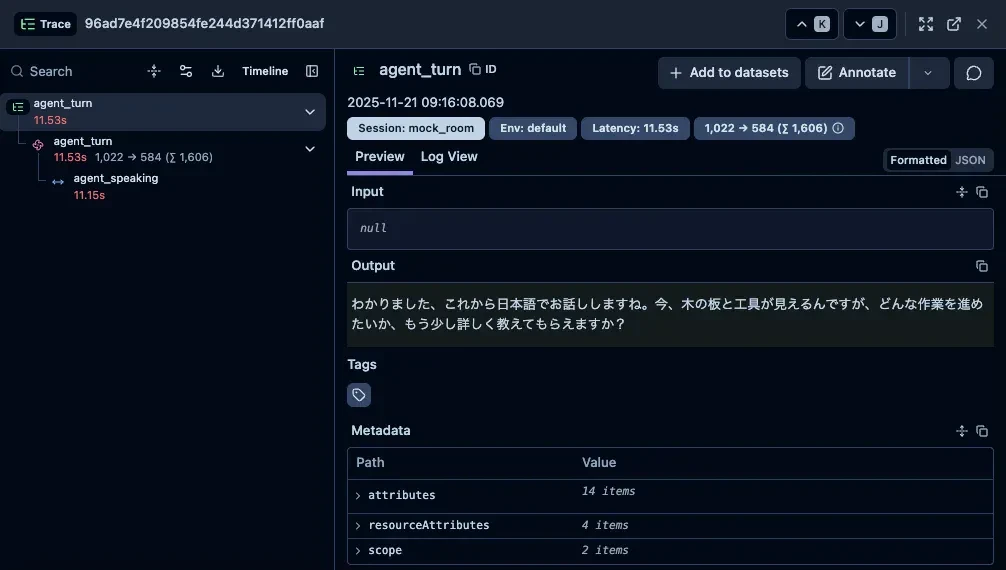
なぜトレースが分離するのか#
LiveKit Agentsは内部で非同期処理を多用しています。各アクティビティ(user_turn、agent_turnなど)は別々の非同期タスクとして実行されますが、その際にOpenTelemetryのコンテキストが適切に伝播されないことがあります。
OpenTelemetryでは、スパン作成時に「現在のコンテキスト」を参照して親子関係を構築します。しかし、非同期タスクが新しいコンテキストで実行されると、親スパンへのリンクが失われ、新しいトレースIDが生成されてしまいます。
この問題を解決するには、プログラム全体で共通のトレースIDを使用し、すべてのスパンがこのトレースIDを継承するように明示的に設定する必要があります。
解決策とOpenTelemetryのコンテキスト管理#
基本的なアプローチ#
プログラム起動から終了までを1つのトレースとして扱うため、カスタムのトレースIDを生成し、すべてのスパンがこのトレースIDを継承するようにします。
実装手順#
ステップ1: 必要なモジュールのインポート#
まず、OpenTelemetryのコンテキスト管理に必要なモジュールをインポートします。
from opentelemetry import trace
from opentelemetry.trace import NonRecordingSpan, SpanContext, TraceFlags
import hashlibステップ2: グローバルトレースIDの生成#
プログラム起動時に、固定のトレースIDを生成します。プログラム起動時に1回だけ生成するようにグローバル変数としています。
# プログラム起動時に固定のtrace_idを生成
# プログラム起動から終了までに使用するルームセッションで同じtrace_idを使用することで、
# すべてのアクティビティを1つのtraceにまとめる
GLOBAL_TRACE_ID = int(hashlib.sha256(os.urandom(16)).hexdigest()[:32], 16)ステップ3: SpanContextの作成とコンテキスト設定#
entrypoint関数内で、カスタムトレースIDを使用したSpanContextを作成し、グローバルコンテキストとして設定します。
@server.rtc_session()
async def entrypoint(ctx: JobContext):
# グローバルなtrace_idを使用
trace_id_int = GLOBAL_TRACE_ID
# trace_idを設定するためのSpanContextを作成
span_context = SpanContext(
trace_id=trace_id_int,
span_id=int.from_bytes(os.urandom(8), "big"), # ランダムなspan_id
is_remote=False,
trace_flags=TraceFlags(TraceFlags.SAMPLED),
)
# カスタムtrace_idでコンテキストを設定
non_recording_span = NonRecordingSpan(span_context)
ctx_with_span = trace.set_span_in_context(non_recording_span)
# コンテキストをグローバルに設定
# これにより、LiveKit Agentsが作成するすべてのスパンがこのコンテキストを継承
token = trace.context_api.attach(ctx_with_span)コードの解説
- NonRecordingSpan: 実際には記録されないスパン。コンテキスト伝播のためだけに使用します。
- trace.set_span_in_context: スパンをコンテキストに設定します。
- trace.context_api.attach: コンテキストをグローバルに設定し、後でデタッチするためのtokenを返します。
ステップ4: try-finallyでコンテキスト管理#
コンテキストを設定した後は、必ずデタッチする必要があります。try-finallyブロックを使用して、確実にクリーンアップを行います。
try:
# set up the langfuse tracer(コンテキスト設定後に呼び出す)
trace_provider = setup_langfuse(
metadata={
"langfuse.session.id": ctx.room.name,
"room.name": ctx.room.name,
}
)
async def flush_trace():
trace_provider.force_flush()
ctx.add_shutdown_callback(flush_trace)
session = AgentSession(vad=silero.VAD.load())
@session.on("metrics_collected")
def _on_metrics_collected(ev: MetricsCollectedEvent):
metrics.log_metrics(ev.metrics)
await session.start(agent=Kelly(), room=ctx.room)
finally:
# コンテキストをデタッチ
trace.context_api.detach(token)重要なポイント
- setup_langfuse()は必ずコンテキスト設定後に呼び出します。
- finallyブロックで確実にデタッチし、コンテキストのリークを防ぎます。
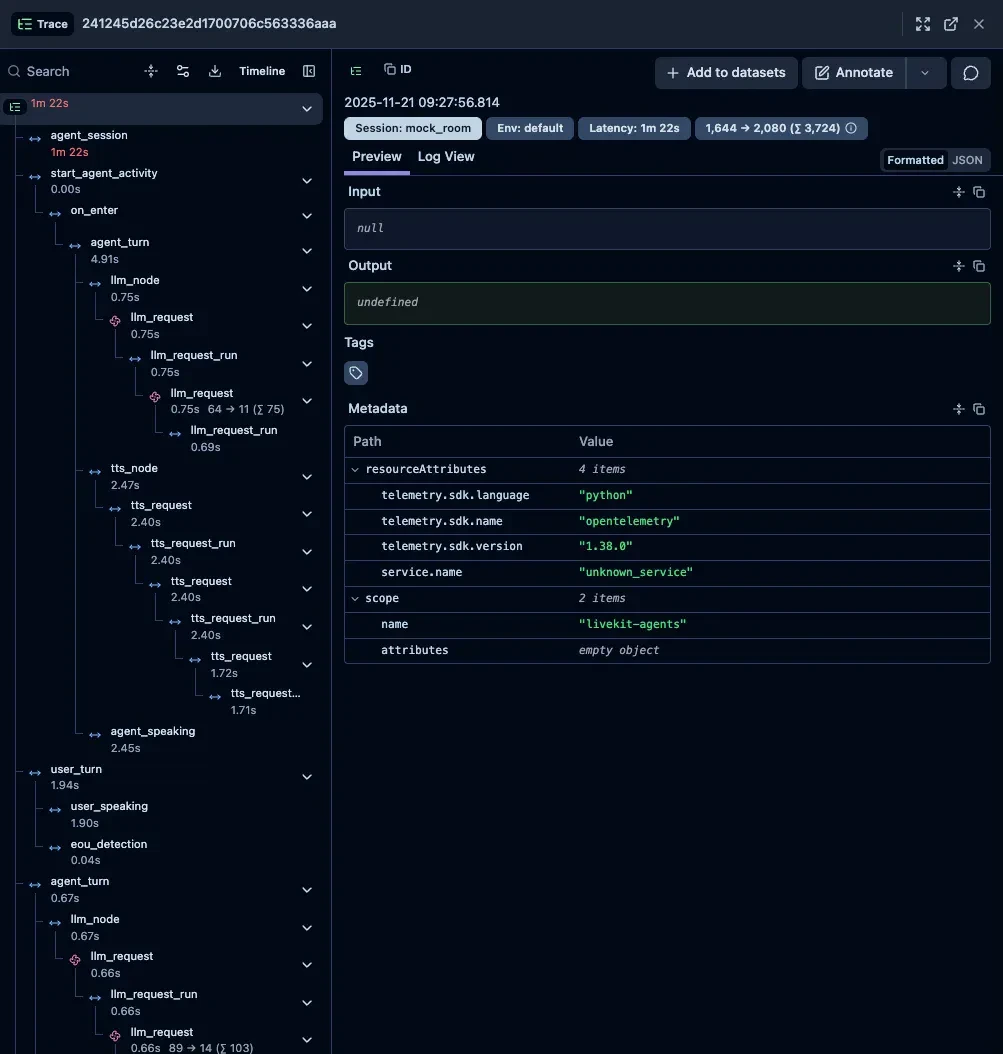
修正後のトレース構造#
トレース一覧の変化#
修正後は、すべてのアクティビティが1つのトレースに統合されました。

トレース詳細#
タイムライン表示#
タイムライン表示では、時系列で処理の流れが可視化されます。
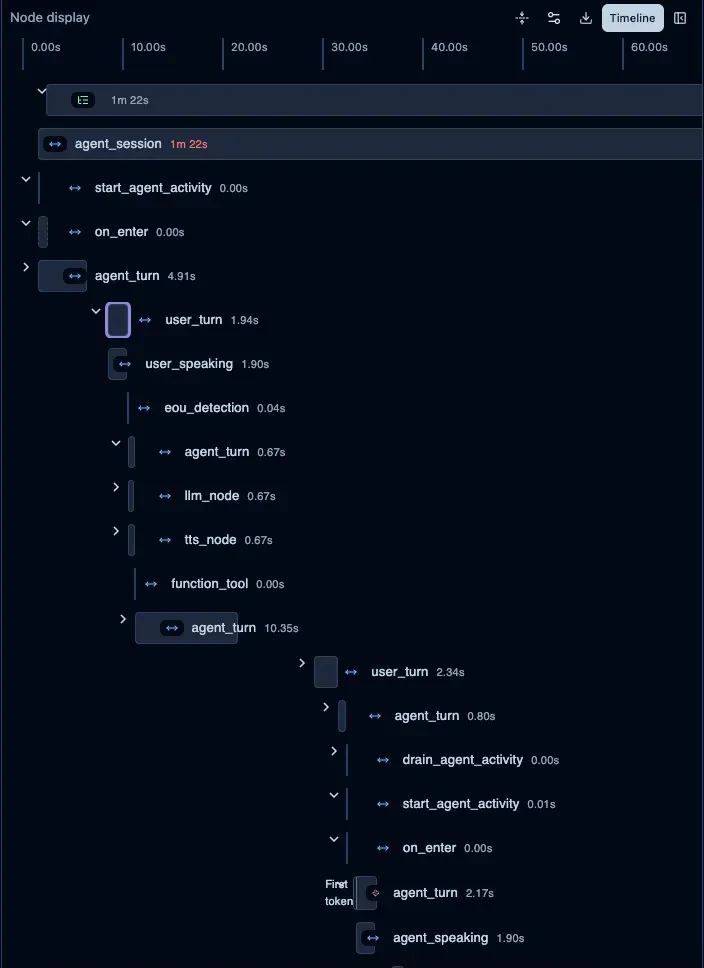

改善された点#
- すべてのアクティビティが1つのトレースに統合されました。
- 親子関係が正しく表現されるようになりました。
- 時系列での処理フローが追跡可能になりました。
- ボトルネックの特定が容易になりました。
- エージェント交代などの複雑なフローも明確に可視化されるようになりました。
まとめ#
今回、LiveKit Agentsを使用して音声AIアプリケーションを構築し、Langfuseによる観測可能性を実装しました。
実際に使ってみて、CLIの見やすさや複数エージェント間の切り替えの容易さなど、開発体験の良さを実感しました。特に印象的だったのは、STT+LLM+TTSパイプラインの速度です。当初は遅いのではないかと懸念していましたが、プリエンプティブ生成やストリーミングTTSなどの最適化技術により、約2.33秒という実用的な速度を達成しており、体感的にも自然な会話が可能でした。
一方で、Langfuse統合時にトレースが分離してしまう問題に遭遇しました。この問題は、OpenTelemetryのコンテキストが非同期処理で適切に伝播されないことが原因でした。
カスタムトレースIDを生成し、グローバルコンテキストとして明示的に設定することで、すべてのアクティビティを1つのトレースにまとめることができました。修正後は、タイムライン表示で処理フローが可視化され、ボトルネックの特定も容易になりました。
非同期処理を多用するアプリケーションでOpenTelemetryを使用する際は、コンテキストの明示的な管理が重要です。今回の経験が、同様の問題に直面している方の参考になれば幸いです。