はじめに#
GoogleのVertex AI Geminiが提供するコンテキストキャッシュ機能は、大量のコンテキストを再利用することで、APIコストを大幅に削減できる強力なツールです。しかし、実際にどの程度のコスト削減効果があるのかを可視化するには、一手間加える必要があります。
本記事では、オープンソースのLLM監視プラットフォームであるLangfuseとGeminiのコンテキストキャッシュを組み合わせ、キャッシュ効果を定量的に監視し、コストの内訳を詳細に把握する方法を解説します。
必要なツール#
- Google Cloud Platform: Vertex AI API 有効化済み
- Langfuse: OpenSourceの LLM Engineering Platform
- Python 実行環境: uv または pip でパッケージ管理
実現できること#
Before(従来)#
- キャッシュを利用しているものの、具体的な効果が不明確
- コストの内訳(通常入力 vs キャッシュ)が見えない
- レイテンシ改善効果が分からない
After(本手法)#
📊 Langfuse ダッシュボード表示例:
├── 入力トークン: 15 → $0.0000045
├── キャッシュトークン: 1,189 → $0.0000891
├── 出力トークン: 1,291 → $0.0032275
├── 合計コスト: $0.0033211
└── レイテンシ: 自動測定実装手順#
ステップ 1: Langfuse でモデル定義を設定#
※ 今回は、gemini-2.5-flashを利用する前提で手順の説明をします。
Langfuse ダッシュボードにログイン
Settings > Modelsでgemini-2.5-flashを探し、右のCloneを選択
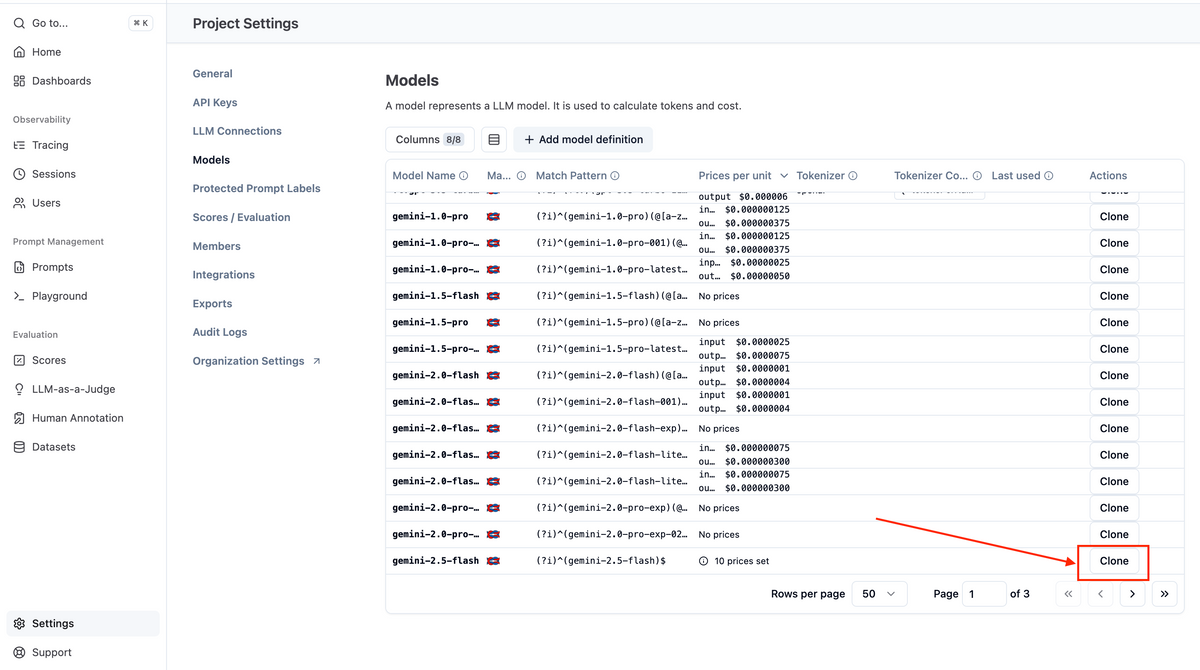
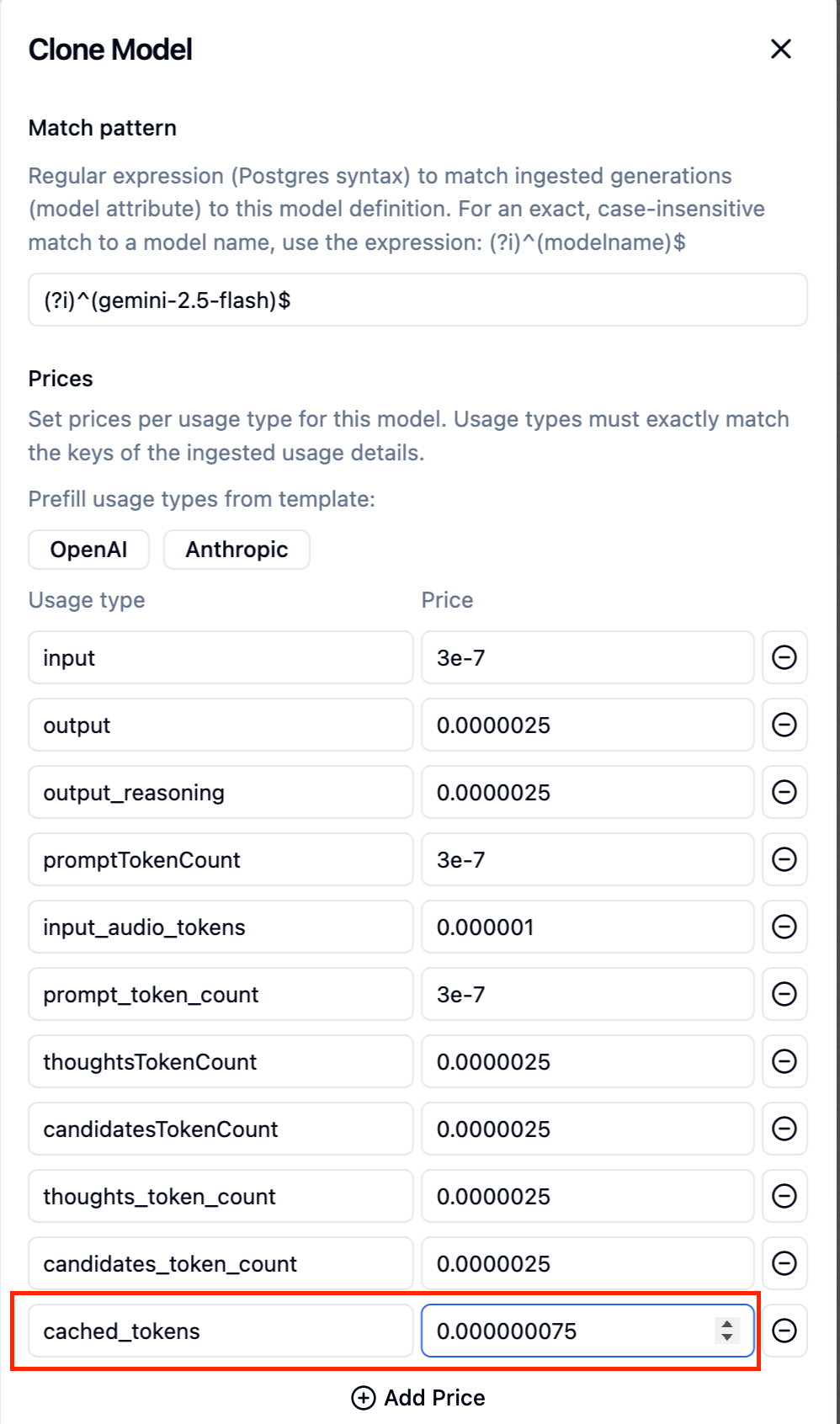
- モデルにキャッシュの価格を追加する
今回は、gemini-2.5-flashにcached_tokensとして$0.000000075(2025年8月時点の金額)と入力
ステップ 2: コンテキストキャッシュを作成#
- ライブラリインストール
google-generativeai
langfuse
python-dotenv- 環境変数定義 (envファイル作成)
### .env
LANGFUSE_PUBLIC_KEY=[パブリックキー]
LANGFUSE_SECRET_KEY=[シークレットキー]
LANGFUSE_HOST=[langfuseのホストURL]
GOOGLE_CLOUD_PROJECT=[自身のGoogle Cloud Project ID]
GOOGLE_CLOUD_LOCATION=global- 大量のコンテキストデータを準備(例:長い文書、FAQ、マニュアル、PDF)
今回は長いテキストの文章をキャッシュに入れるようなサンプルになってます。 2. Vertex AI Clientでキャッシュを作成
📖 公式ドキュメント: Context Cache Create - Google Cloud
from google.genai.types import Content, CreateCachedContentConfig, Part
content_cache = client.caches.create(
model="gemini-2.5-flash",
config=CreateCachedContentConfig(
contents=[Content(role="user", parts=[Part.from_text(text=long_context)])],
ttl="3600s", # 1時間有効
),
)
print(f"キャッシュID: {content_cache.name}")キャッシュを作成するのには以下の制限があります。
- 最小キャッシュサイズ: 1,024 トークン以上のコンテンツが必要(Gemini 2.5 Flash)
- 最大コンテンツサイズ: 10MB まで
- TTL 制限: 最小 1 分、最大制限なし
制限詳細: Google Cloud 公式制限表
- コンテキストキャッシュ作成時のprint文で表示されたキャッシュID
(例:projects/xxx/locations/global/cachedContents/123)を保存します。
次の呼び出しで使用するため、環境変数に入れておくと便利です。
# .env GEMINI_CACHE_ID=projects/xxx/locations/global/cachedContents/123ステップ 3: Langfuse 統合コードの実装#
3-1. 使用量データの正確な取得#
Gemini APIでは、モデルを呼び出した後のレスポンス内にトークン使用数が含まれています。このレスポンスから得られたトークン数をLangfuseに渡す必要があります。
# キャッシュIDを使用してGemini呼び出し
cache_id = "projects/xxx/locations/global/cachedContents/123"
# ステップ2で取得
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="あなたの質問をここに入力",
config=GenerateContentConfig(cached_content=cache_id)
)
# APIレスポンスから直接取得
usage_metadata = response.usage_metadata
cached_tokens = getattr(usage_metadata, "cached_content_token_count", 0)
input_tokens = getattr(usage_metadata, "prompt_token_count", 0) - cached_tokens
output_tokens = getattr(usage_metadata, "candidates_token_count", 0)補足#
- キャッシュから供給されたトークン数は、呼び出し後の response.usage_metadata.cached_content_token_count に入ります
- GenerateContentConfig(cached_content=cache_id) を付けて呼び出す必要があります。
- prompt_token_count は「プロンプト全体(キャッシュ分を含む)」のトークン数です。
- 通常課金される入力トークンは、全体からキャッシュ分を引いた数で算出をしています。
3-2. Langfuse トレース実装#
このサンプルで行っていること(流れ)
- @observe(…, as_type=“generation”) で関数を計測対象にし、レイテンシを自動取得
- GenerateContentConfig(cached_content=cache_id) を指定して Gemini を呼び出し
- レスポンス usage_metadata から cached_content_token_count などの使用量を取得
- 課金対象の入力トークンを prompt_token_count - cached_content_token_countで算出
- update_current_generation に model/input/output/usage_details/metadata を渡して Langfuse に送信
- モデル定義の単価に基づき、Langfuse 側でコストが自動計算・可視化
サンプルソースコード
import os
from typing import Any
from dotenv import load_dotenv
from google import genai
from google.genai.types import GenerateContentConfig, HttpOptions
from langfuse import get_client, observe
load_dotenv()
def build_clients() -> tuple[genai.Client, Any]:
_ = get_client()
project_id = os.getenv("GOOGLE_CLOUD_PROJECT")
location = os.getenv("GOOGLE_CLOUD_LOCATION")
client = genai.Client(
vertexai=True,
project=project_id,
location=location,
http_options=HttpOptions(api_version="v1"),
)
return client, _
@observe(name="gemini-cached-call", as_type="generation")
def call_gemini_with_cache(
client: genai.Client,
cache_id: str,
query: str,
model_name: str = "gemini-2.5-flash",
) -> str:
"""Call Gemini with context cache and report usage to Langfuse."""
response = client.models.generate_content(
model=model_name,
contents=query,
config=GenerateContentConfig(cached_content=cache_id),
)
usage = response.usage_metadata
cached_tokens = getattr(usage, "cached_content_token_count", 0)
input_tokens = max(0, getattr(usage, "prompt_token_count", 0) - cached_tokens)
output_tokens = getattr(usage, "candidates_token_count", 0)
langfuse_client = get_client()
langfuse_client.update_current_generation(
model=model_name,
input=query,
output=(response.text or ""),
usage_details={
"input": input_tokens,
"cached_tokens": cached_tokens,
"output": output_tokens,
},
metadata={
"cache_id": cache_id,
"provider": "vertex-ai",
},
)
return response.text or ""
def main() -> None:
client, langfuse_client = build_clients()
# Example placeholders for blog readers
cache_id = os.getenv(
"GEMINI_CACHE_ID", "projects/[Project ID]/locations/global/cachedContents/[cache_number]",
)
query = "データサイエンスについて教えて"
_ = call_gemini_with_cache(client, cache_id, query)
# Ensure data is flushed to Langfuse backend in short-lived processes
langfuse_client.flush()
if __name__ == "__main__":
main()Langfuseダッシュボード可視化#
以下の画像のように、キャッシュトークンが別途コストとして出力されています。
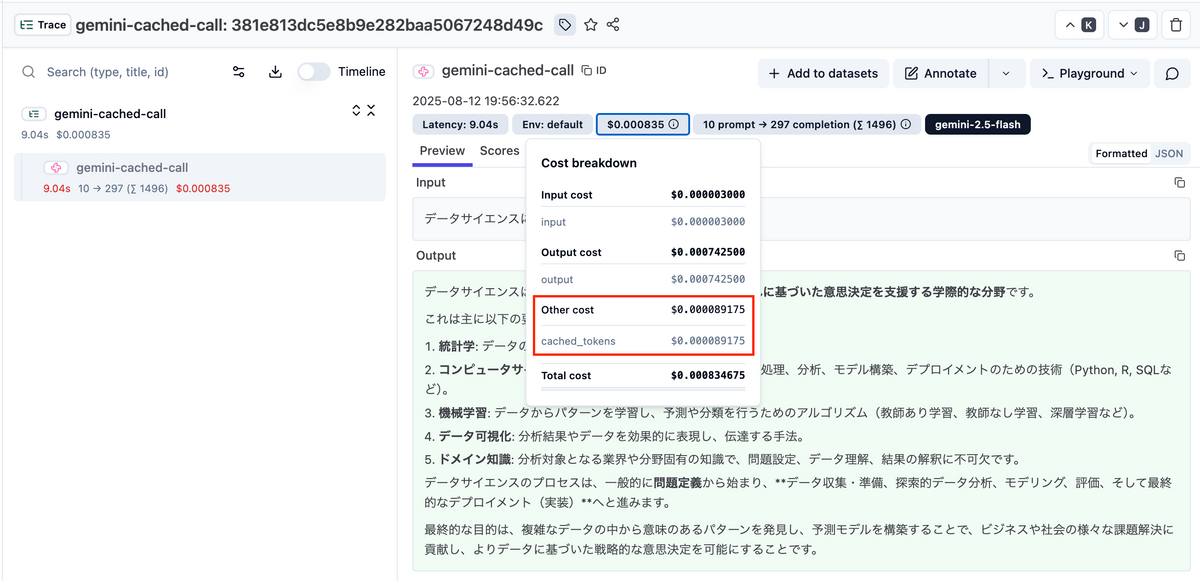
命名の注意点
- input, output という名前を入れた変数を設定すると、それぞれ Input cost, Output cost に分類されます。
例:cached_input_tokensと命名し、モデル価格をセットすると以下のようにinput costとして描画されるようになります。
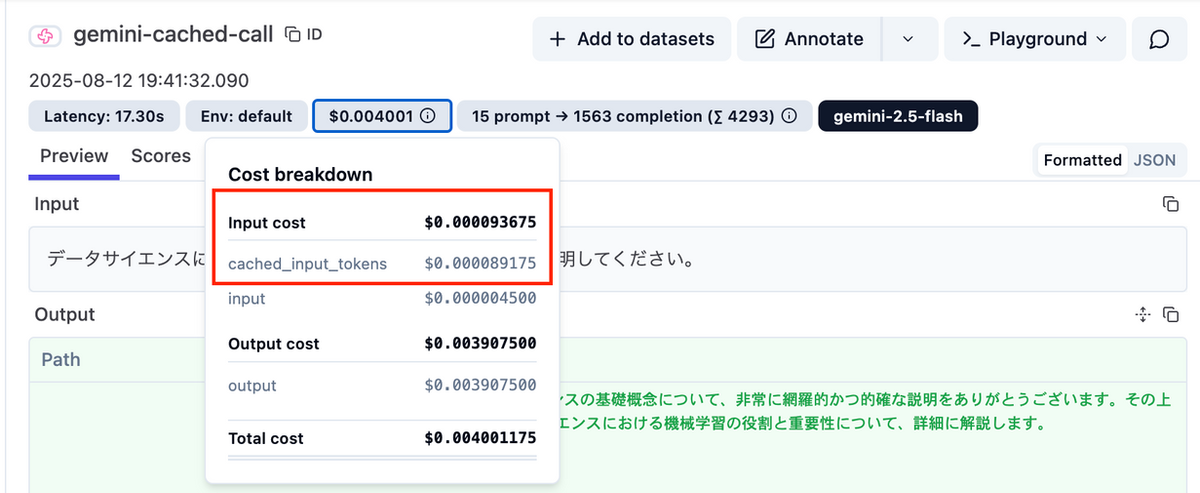
- キャッシュコストを独立して表示したい場合は cached_tokens など別の名前を使用してください。
- cached_tokens は Other cost として独立したカテゴリで表示されます。
まとめ#
この手法により、以下を実現できます
- 透明性: キャッシュ効果の可視化
- 自動化: 手動計算不要のコスト監視
- 継続性: 長期的なコスト最適化
- スケール: 大規模システムでの運用
Gemini のコンテキストキャッシュと Langfuse を組み合わせることで、生成AIの「コスト」「レイテンシ」「再利用性」を定量的にコントロールできます。特に、長文コンテキストやPDF・動画等のマルチモーダルのデータの再利用が多いワークロードでは、入力コストの削減と応答時間の短縮が同時に見込め、AI アプリケーションの運用効率を大幅に向上させることができると思いますので、ぜひGemini のコンテキストキャッシュと Langfuseを利用して、生成AIアプリケーションの開発を進めていただけると嬉しいです。