こんにちは。ガオ株式会社の黒澤です。この記事では、AIエージェントに記憶を持たせるメモリレイヤー mem0 を Google Cloud 上で動かし、その挙動を検証します。
結論を先に述べると、mem0 は会話から「ユーザーごとの事実」を LLM で抽出して保存し、後から関連する記憶をベクトル検索で取り出してプロンプトに渡します。再学習も検索基盤の作り込みも要らず、add と search だけでユーザー単位の記憶が溜まっていきます。今回は LLM・Embedder ともに Google Cloud の Vertex AI(Gemini Enterprise Agent Platform、旧 Vertex AI)を API キーなしで呼び、保存先を pgvector(PostgreSQL)とする構成で、記憶の保存・想起から、記憶を使うエージェント、複数エージェント間での共有まで動かしました。
本記事でわかること # 対象環境: 本記事の内容はLangfuse Cloud環境が対象です。セルフホスト環境では現時点でMonitors機能は利用できません。
TL;DR # 後編で指摘した NFKD 正規化の不整合(カウンターとハイライトの食い違い)は、Langfuse 本体の PR #12961 / #13038(v3.166.0)で解消されました。 上流 @codemirror/search に出した PR #19 自体はマージされず、取り下げになりました。 ただしその後、@codemirror/search 6.7.0 で、PR #19 とは異なるアプローチ(マッチに precise フラグを付与し、置換側が安全に弾けるようにする方式)によって SearchCursor の正規化境界の問題に対処されています。 これは PR #19 がそのまま採られたわけでも、Langfuse v3.166.0 の修正そのものでもありません。Langfuse は v3.166.0 時点で @codemirror/search を ^6.6.0 と宣言しており、本記事執筆時点の main では ^6.7.0 に引き上げられています。 はじめに # 以前、Langfuse v3.158.0 で追加されたメッセージウィンドウ内検索機能(PR #12578)について、2回に分けて記事を書きました。
本記事でわかること # LLM-as-a-Judgeの「苦手な評価」とは何か Langfuseのコード評価(Code Evaluators)機能の概要と使い方 コード評価をLLM評価と組み合わせた実践的な運用パターン INACTIVEなエバリュータへの手動バッチ実行を活用した安全な本番導入フロー 対象読者 # LangfuseでLLM-as-a-Judgeを使っているエンジニア 評価コストや判定のブレに課題を感じている方 Langfuseの評価機能を本番導入する前に安全に試したい方 LLM-as-a-Judgeだけでは足りないケース # LLMアプリを本番運用していると、こんな疑問が浮かぶことがあります。「この評価、本当にLLMが必要?」
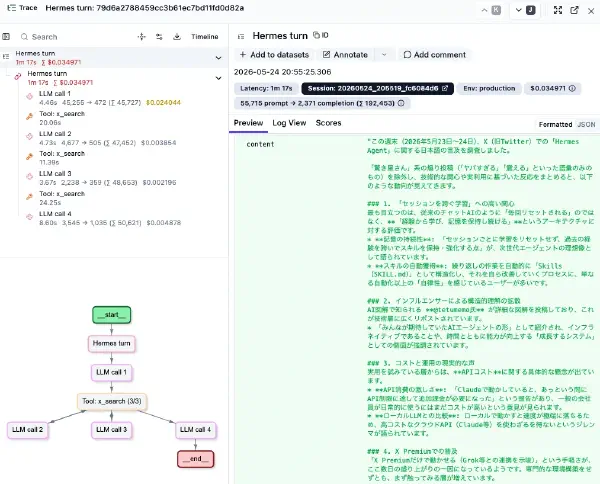
ガオ株式会社では、社内およびグループ企業間の業務で自律型エージェント Hermes Agent (NousResearch/hermes-agent) の活用を進めています。
エージェントが Tool を呼び出しながら自律的に業務を進めるようになると、LLM API call 単位のログだけでは挙動を追いきれません。さらに自律型エージェントの場合、人手が介在せず判断と実行が連続して走るため、観測性 — 後から誰が何を要求し、エージェントが何を判断し、どの Tool をどう実行したかを追える状態 — が、従来以上にガバナンスや内部統制の観点で重要になります。
こんにちは。ガオ株式会社の黒澤です。LangfuseのCloud版にて、Experiments が独立した機能としてメニューから選択できるようになりました。本記事では、Experimentsでどのようなことができるのかということを、変更点や動作確認を交えて解説します。
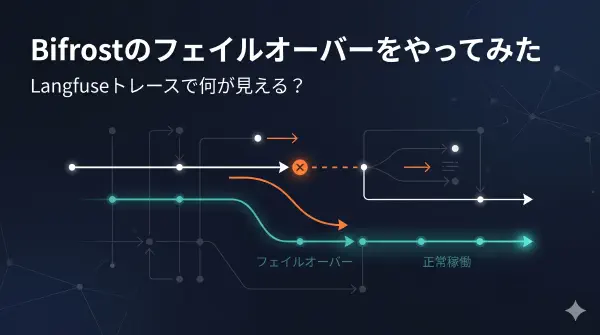
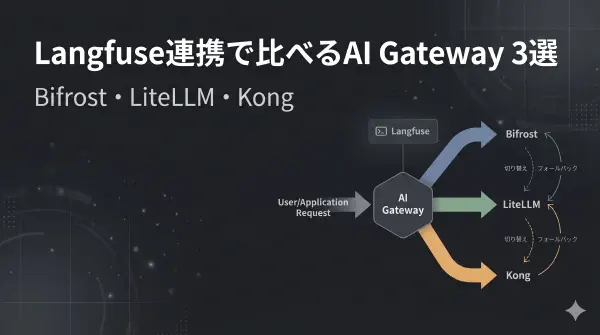
こんにちは。ガオ株式会社の黒澤です。前回 の記事では、AI Gatewayの製品を3つ紹介しました。この記事では、その中からBifrostを使用して、フォールバック機能がどのように動作して、Langfuseで可視化されるかを解説します。
こんにちは。ガオ株式会社の黒澤です。LLMアプリケーションを複数開発する環境では、それらを統合する基盤であるAI Gatewayを活用するケースがあります。本記事では、AI Gatewayとして3つの製品を、Langfuseと組み合わせた場合のポイントとともに解説します。
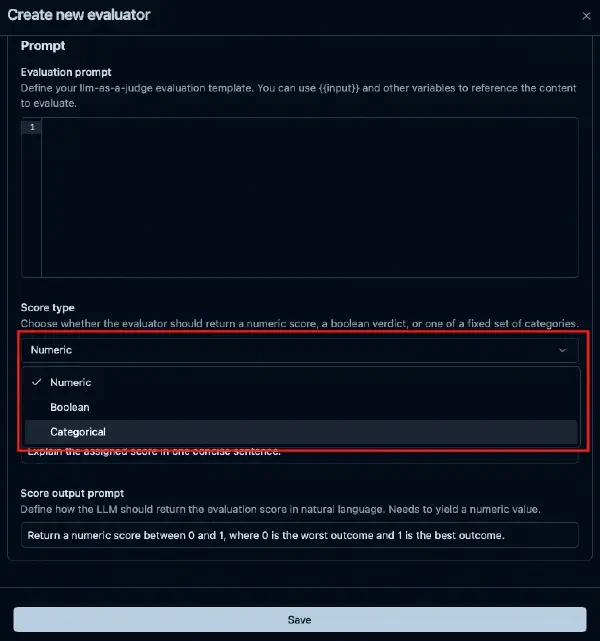
本記事でわかること # LLM-as-a-Judgeで数値スコアを使うことの問題点 Langfuseのカテゴリ型・Boolean型スコアを使って、直感的な Evaluator を設計する方法 JSON Schemaによる型安全な評価出力の仕組み RAG精度・コンテンツ安全性・サポートチケット分類など実務ユースケースへの適用例 対象読者 # Langfuseで LLM-as-a-Judge(自動評価)を運用している方 評価スコアのしきい値設定に迷いを感じている方 評価結果をダッシュボードで分析しやすくしたい方 「0.7以上なら合格」という設計の脆さ # 本番LLMアプリの評価パイプラインを運用していると、自動評価(LLM-as-a-Judge)はもはや欠かせない仕組みです。人間がすべてのトレースをレビューするのは非現実的なため、LLMに評価させるアプローチが普及してきました。
こんにちは。ガオ株式会社の黒澤です。以前「LLMOpsとは? MLOpsとの違いや生成AIの評価について解説 」で LLMOps の全体像を整理しました。
こんにちは。ガオ株式会社の黒澤です。本記事は「LLMOps:評価基盤の設計編 — Langfuse 活用 」の続編です。
設計編では評価軸の定義から Judge プロンプト設計・ゴールデンデータセット構築・メタ評価(Cohen’s Kappa・Confusion Matrix)まで解説しました。本記事ではその後の「誰が・いつ・どうやって評価を運用するか」を整理します。
本記事でわかること # Langfuseにおける「管理者によるトレース閲覧の検知」というニッチだが重要な課題に対して、実機検証ベースで現状の選択肢を整理します。