Langfuse の公式ドキュメントに掲載されている Cookbook「Migrating Data Between Langfuse Projects (Python SDK v4) 」を、4 つの移行パターンで実際に実行してみました。移行はおおむね成功しましたが、UI に出るものと出ないものが分かれ、見落としやすい落とし穴がいくつかありました。本記事では、特定の検証環境における観測結果と再現時の注意点を整理します。Cloud / セルフホスト / リージョンによる差分が Langfuse の正式仕様なのか、Feature flag や Preview UI・検証時点の実装差なのかは、本記事の範囲では切り分けていません。
TL;DR # 後編で指摘した NFKD 正規化の不整合(カウンターとハイライトの食い違い)は、Langfuse 本体の PR #12961 / #13038(v3.166.0)で解消されました。 上流 @codemirror/search に出した PR #19 自体はマージされず、取り下げになりました。 ただしその後、@codemirror/search 6.7.0 で、PR #19 とは異なるアプローチ(マッチに precise フラグを付与し、置換側が安全に弾けるようにする方式)によって SearchCursor の正規化境界の問題に対処されています。 これは PR #19 がそのまま採られたわけでも、Langfuse v3.166.0 の修正そのものでもありません。Langfuse は v3.166.0 時点で @codemirror/search を ^6.6.0 と宣言しており、本記事執筆時点の main では ^6.7.0 に引き上げられています。 はじめに # 以前、Langfuse v3.158.0 で追加されたメッセージウィンドウ内検索機能(PR #12578)について、2回に分けて記事を書きました。
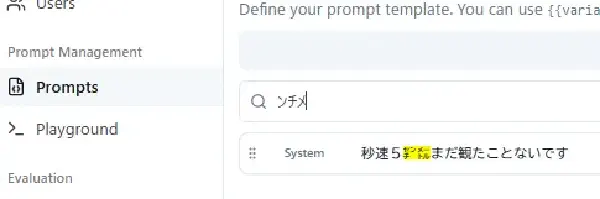
ガオ株式会社では、社内およびグループ企業間の業務で自律型エージェント Hermes Agent (NousResearch/hermes-agent) の活用を進めています。
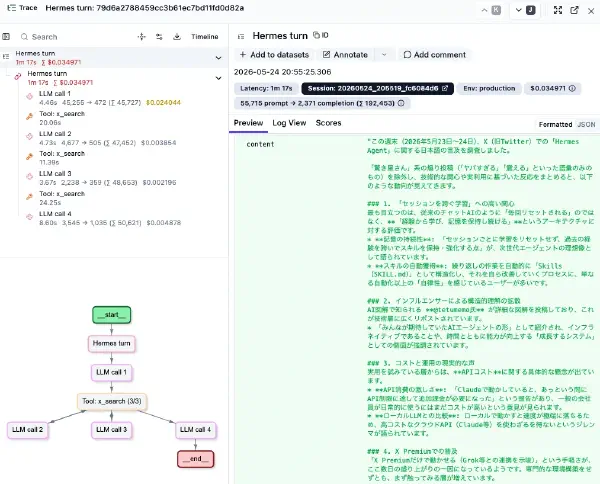
エージェントが Tool を呼び出しながら自律的に業務を進めるようになると、LLM API call 単位のログだけでは挙動を追いきれません。さらに自律型エージェントの場合、人手が介在せず判断と実行が連続して走るため、観測性 — 後から誰が何を要求し、エージェントが何を判断し、どの Tool をどう実行したかを追える状態 — が、従来以上にガバナンスや内部統制の観点で重要になります。
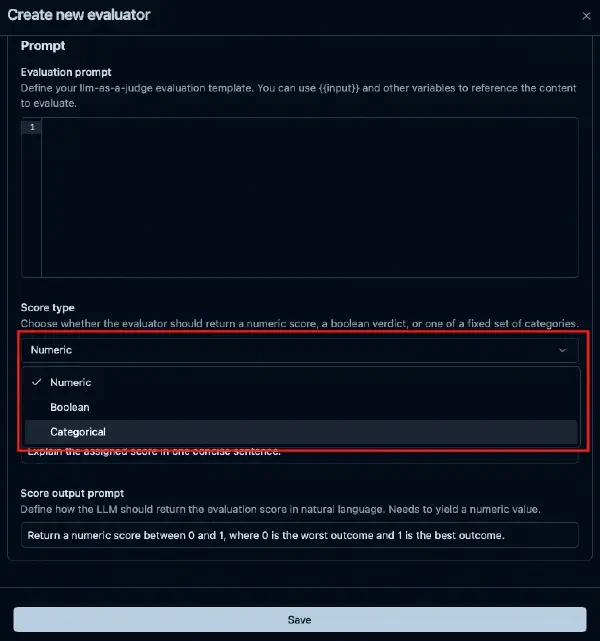
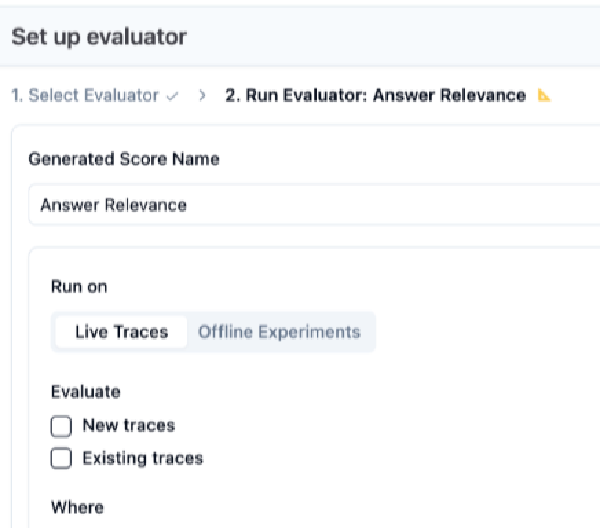
本記事でわかること # LLM-as-a-Judgeで数値スコアを使うことの問題点 Langfuseのカテゴリ型・Boolean型スコアを使って、直感的な Evaluator を設計する方法 JSON Schemaによる型安全な評価出力の仕組み RAG精度・コンテンツ安全性・サポートチケット分類など実務ユースケースへの適用例 対象読者 # Langfuseで LLM-as-a-Judge(自動評価)を運用している方 評価スコアのしきい値設定に迷いを感じている方 評価結果をダッシュボードで分析しやすくしたい方 「0.7以上なら合格」という設計の脆さ # 本番LLMアプリの評価パイプラインを運用していると、自動評価(LLM-as-a-Judge)はもはや欠かせない仕組みです。人間がすべてのトレースをレビューするのは非現実的なため、LLMに評価させるアプローチが普及してきました。
本記事でわかること # Langfuseにおける「管理者によるトレース閲覧の検知」というニッチだが重要な課題に対して、実機検証ベースで現状の選択肢を整理します。
こんにちは。ガオ株式会社の黒澤です。この記事では、Langfuseでトレースに非公開な画像を表示する場合に、Google Cloud Storage(以下、GCS)を用いた場合のアーキテクチャパターンについて、実装を踏まえてご紹介します。
はじめに # この記事では、オープンソースのチャットUI「LibreChat」をDocker Composeでセットアップし、既存のLangfuseへトレースを送信する機能を試します。
LMアプリケーションの可観測性(オブザーバビリティ)を確保しようとする際、Langfuse SDK や OpenTelemetry SDK をアプリケーション側に組み込んで計装するのが一般的なアプローチですが、これは多少なりとも手間がかかることと、社内のエージェントを勝手に動かす人などが意図的に観測されないように対応しないこともありえるでしょう。
LLMアプリケーションの開発で、こんな経験はないでしょうか。
「先週と同じ条件で実験したいのに、データセットを更新したから再現できない…」
「評価データを改善したいけど、過去の結果と比較できなくなるのが怖い…」
こんにちは。ガオ株式会社の黒澤です。
Langfuse v3.153.0 で [PR #11861 ](https://github.com/langfuse/langfuse/pull/11861 ) がマージされ、LLM-as-a-Judge を Observation 単位で実行できるようになりました。本記事ではその背景と使い方をまとめます。
Google ADK(Agent Development Kit)のトレースに Langfuse のプロンプト情報を紐付ける方法を解説します。これにより、プロンプトごとのコスト・レイテンシ分析や A/B テストが可能になります。
更新日:2月2日
本記事では、LangfuseのTrace詳細画面で利用できる主要な特殊レンダリングパターンを解説します。これらのパターンを活用することで、トレース情報をより視覚的かつ構造的に表示できます。